Wide & Deep Learning for Recommender Systems
선형적인 모델(Wide)과 비선형적인 모델(Deep)을 결합하여 기존 모델들의 장점을 모두 취하고자 한 논문
등장 배경
추천시스템에서 해결해야 할 두 가지 과제
-
Memorization — 학습데이터에 자주 등장하는 패턴은 모델이 암기해야 한다.
함께 빈번히 등장하는 아이템 혹은 특성(feature) 관계를 과거 데이터로부터 학습하는 것
Logistic Regression과 같은 선형 모델
- 대규모 추천 시스템 및 검색 엔진에서 사용해왔다.
- 확장 및 해석이 용이하다.
- 학습 데이터에 없는 feature 조합에 취약하다.
-
Generalization — 학습데이터에 발생하지 않는 패턴을 적절하게 표현해야 한다.
드물게 발생하거나 전혀 발생한 적 없는 아이템/특성 조합을 기존 관계로부터 발견하는 것
FM, DNN과 같은 임베딩 기반 모델
- 일반화가 가능하다.
- 고차원의 Sparse 데이터로 임베딩을 만들기가 어렵다.
이 둘을 결합하여 사용자의 검색 쿼리에 맞는 앱을 추천하는 모델을 제안한다.
모델 구조
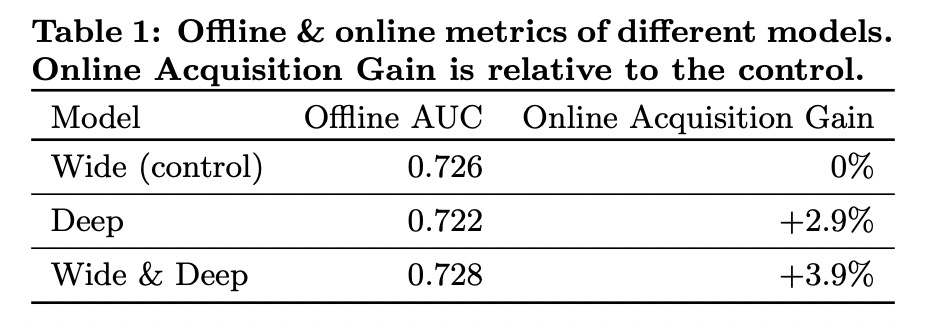
Wide(Memorization Model)
선형 모델과 거의 비슷한 모델
Generalized Linear Model
$**\tt y = w^Tx + b**$
${\tt w = [w_1,...,w_n]}$$\tt x = [x_1,...,x_n]$$b \in \R$
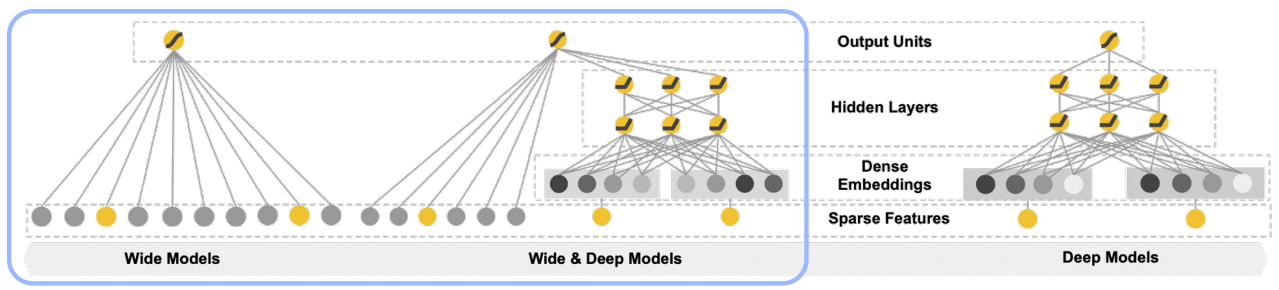
이와 같은 구조만으로는 두 변수의 관계를 파악할 수 없다.
Cross-Product Transformation
서로다른 두 변수의 관계를 학습하기 위해 Cross-Product Term을 추가해준다.
$$
\tt \phi_k(x) = \Pi^d_{i=1}x_i^{c_{ki}}, \quad c_{ki} \in \{0,1\}
$$
이 때, 가능한 모든 변수들 간의 내적을 표현하면 학습해야 할 파라미터가 너무 많아지게 된다.
따라서, 해당 모델에서는 주요 feature 2개에 대한 second-order Cross Product만 사용한다.
위의 모델링은 Polynomial Logistic Regression과 거의 동일하다.
$$
\hat y(x)=\left(w_0+\sum_{i=1}^n w_i x_i{+\sum_{i=1}^n \sum_{j=i+1}^n w_{i j} x_i x_j}\right), \quad w_i, w_{i j} \in \mathbb{R}
$$
이 모델로는 $n^2$만큼 학습 파라미터가 늘어나게 된다.
즉, Wide Component만으로는 표현할 수 있는 상호작용의 한계가 명확하다.
Deep(Generalization Model)
단순한 구조.
-
Feed-Forward Neural Network
3 layer로 구성되었으며, ReLU 함수를 사용
연속형 변수는 그대로 사용하고, 카테고리형 변수는 피쳐 임베딩 후 사용
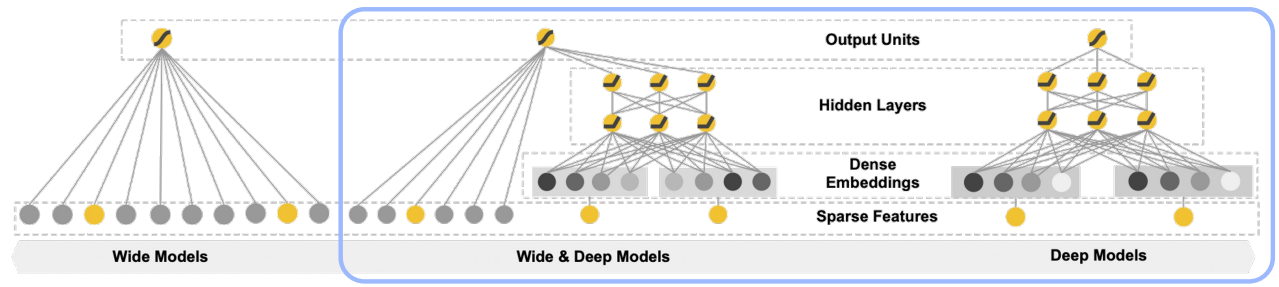
전체 구조 및 손실 함수
$$
P(Y=1|x) = \tt\sigma(w^T_{wide}[x,\phi(x)] + w^T_{deep}a^{(lf)} + b)
$$
$\tt x:$ 주어진 n개의 변수
$\tt \phi(x):$ n개 변수간의 상호작용(Cross-Product)
위에서 언급한 것처럼, [사용자가 과거에 설치한 앱]과 [사용자가 현재 CTR을 예측할 앱]의 상호작용만 반영한다.
모델 성능
Baseline인 Wide 모델과 Deep 모델은 각각 Offline, Online에서 서로 다른 양상을 보이지만, 두 개 모델을 결합하여 만든 Wide & Deep 모델은 모두 좋은 성능을 보였다.