우선, 시작하기에 앞서 corpus 구성을 확인했다.
한글로 작성되었으며, 제목과 문서 내용으로 구성되어있는 것을 확인했다.
 일단 데이터를 처리하기 위해 코드에서 파일을 열어야 하는데, 문서가 한글파일로 제공되었기 때문에 한글 문서를 txt 문서로 변환해주었다.
일단 데이터를 처리하기 위해 코드에서 파일을 열어야 하는데, 문서가 한글파일로 제공되었기 때문에 한글 문서를 txt 문서로 변환해주었다.
 {: w=“200” h=“100” }
{: w=“200” h=“100” }
언어는 파이썬을 선택했다.
처음 프로젝트를 시작했을 때, 나는 colab 환경에서 파이썬 코드를 실행시키고자 했으므로 Google Drive에 corpus 파일을 업로드하고, 코드 작성을 시작했다.
수업 내용에서는 영어를 기준으로 다뤄왔었는데 한글을 토큰화하는 방법이 떠오르지 않았다.
다행스럽게도 한글 형태소 분석 라이브러리 Konlpy가 있어서 이를 활용하고자 했다.
하지만 해당 Konlpy 라이브러리가 자바를 기반으로 짜여졌고, 파이썬으로 wrapping한 채로 사용하는 방식이었다.
해당 라이브러리를 사용하기 위해서는 라이브러리에서 지원하는 파이썬 버전과 자바 버전이 일치해야 했다.
코랩 환경에서 해당 라이브러리를 사용하기 위해 수많은 블로그를 탐색하고, 깃허브 라이브러리 페이지를 방문하여 issue를 살펴봤었지만 해당 문제는 쉽사리 해결되지 않았다.
그래서 거의 포기하고 직접 문서의 조사를 제거하여 활용하고자 마음 먹고 작업을 수행했다.
하지만 결국 이 과정은 학습에 도움이 되지 않는다고 판단해 colab 환경을 pycharm 환경으로 바꿔서 다시 한번 해보자고 마음먹었고, 시행착오 끝에 라이브러리를 사용할 수 있게 되었다.
라이브러리 활용을 포기하고 직접 문서의 단어를 추출하고 있었다.
한글 단어를 직접 추출하던 코드다. 나의 고통의 흔적이 보인다.
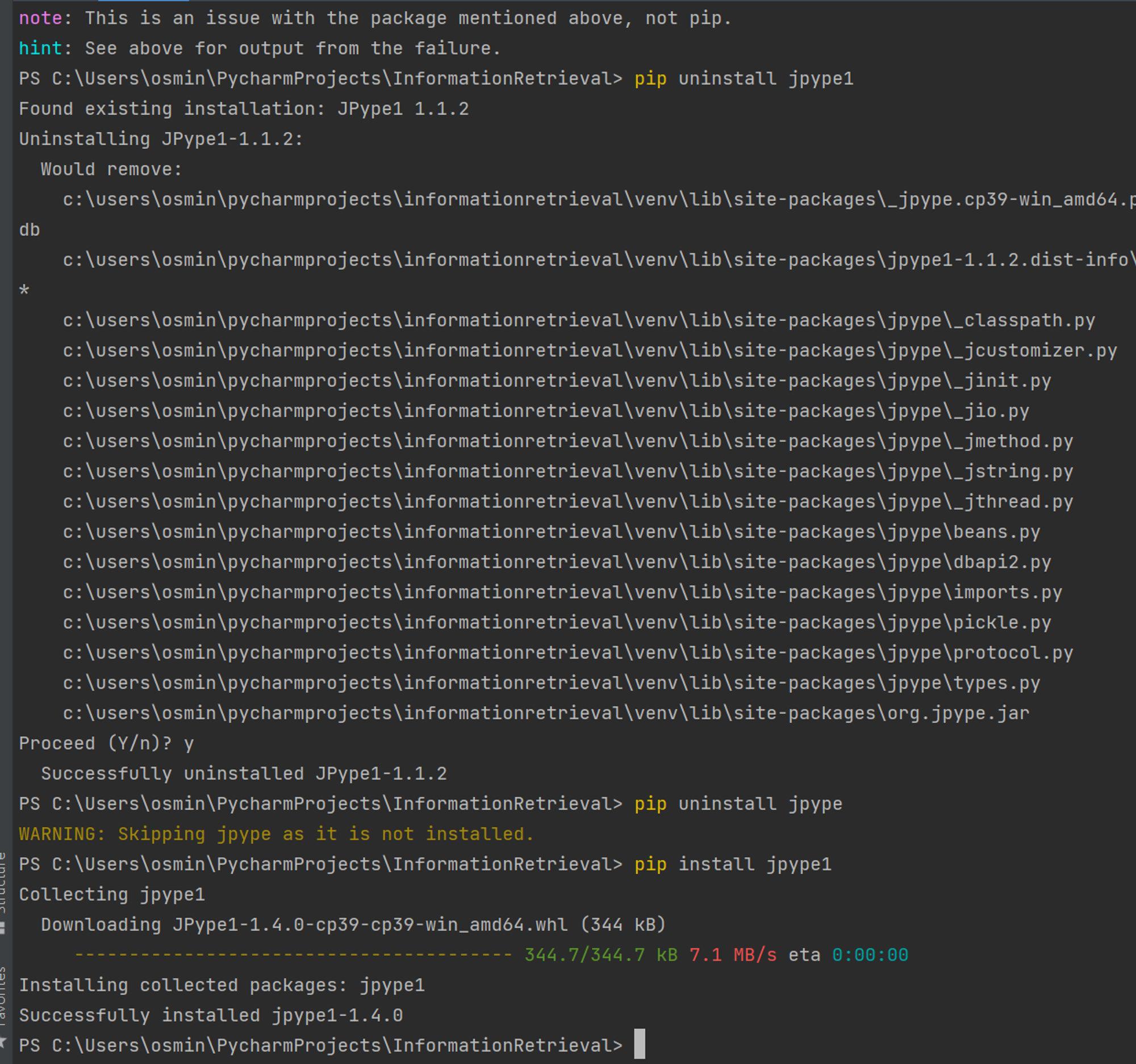
라이브러리 실행을 성공시킨 마지막 명령어.
JPype1.1.2와 JPype3-1, Python 3.6, Python 3.7, Python 3.10의 조합을 활용해보았고, 실행되지 않았다.
하지만 결국 위 사진에서 보이듯이, JPype1의 1.4.0 버전과 python 3.9.5 버전을 활용하여 성공했다.
아래는 내가 문제를 해결하는 데 도움을 받은 글이다.
https://blog.naver.com/myincizor/221624979283
https://ingu627.github.io/tips/install_konlpy/
검색엔진 코드 작성
이후 검색엔진의 코드를 작성하는 것은 어렵지 않았는데, 다만 강의 내용을 완벽히 이해하고 있어야 코드를 수월하게 짤 수 있는 것 같다.
수업에서 배운 대로 tf-idf Weighting을 기준으로 문서의 순서를 매기고, 쿼리를 입력받았을 때 Score가 높은 순서대로 결과를 보여주고자 했다.
이를 구현 순서대로 나열하면 다음과 같다.
1. corpus 파일 읽기: open()함수 활용
file = open("corpus.txt", 'r', encoding='UTF8')
corpus = file.readlines()
corpus = [line[:-1] for line in corpus if line != "\n"]
corpus
2. corpus를 dictionary에 {key: 제목, value: 문서내용 }으로 저장하기.
해당 부분은 문자열 패턴을 추출하고 검사하는 re 라이브러리를 활용하여 비교적 쉽게 수행할 수 있다.
-
해당 지점을 수행하며 기타 오탈자의 존재를 파악했으며 (ex: <title>~~~<title>)
-
특이 사항으로 하나의 제목으로 두 개의 문서 내용을 가진 경우가 있었다.
해당 부분을 처리해주기 위해 dictionary에서 value를 바로 문서 내용으로 하지 않고, 리스트로 만들어서 extend()함수를 통해 두 문서 내용을 이어 붙였다.
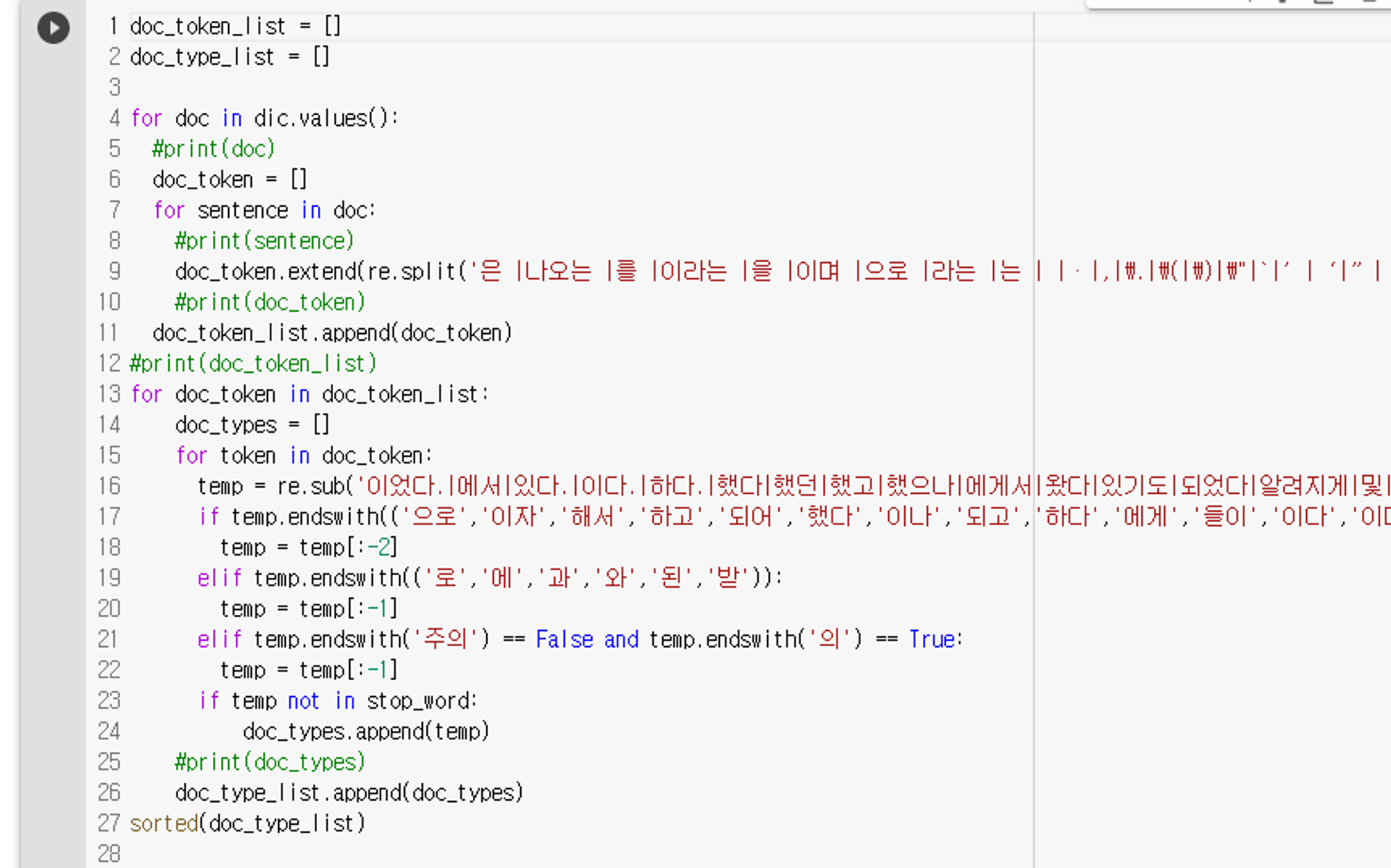
for line in corpus: if re.match("<title>", line): line = re.sub('<title>\d+. |</title>|<title>|\d+.', '', line) # line = line.replace('<title>', '').replace('</title>','') key = line # print(key) dic[key] = [] # value에 해당하는 리스트를 만들어주기. continue else: line = re.sub('\xa0', ' ', line) # print(line) dic[key].append(line) # value 리스트에 문서 내용 담기. for doc in dic.values(): if len(doc) != 1: doc[0] += doc[1] doc.pop()
3. 문서별 term frequency 구하기
문서에 포함되는 단어들의 term frequency를 구해야 했다.
우선 단어의 빈도는 okt 라이브러리를 활용해서 쉽게 구할 수 있었다.
for doc in dic.values():
doc_term = dict(Counter(okt.nouns(doc[0])))
이후, 해당 raw term frequency들을 log frequency weighting으로 바꿔주기 위해 함수를 선언했다.
$$
w_{t, d}=\left\{\begin{array}{cc}1+\log _{10} \mathrm{tf}_{t, d}, & \text { if } \mathrm{tf}_{t, d}>0 \\0, & \text { otherwise }\end{array}\right.
$$
단어의 빈도가 크지 않기 때문에, 나는 log의 base를 2로 설정했다.
def lf_weighting(x):
if x:
return round(1 + math.log(x, **2**), 4) # 소수점 넷째에서 반올림을 수행했다.
else:
return 0
이후 map 함수를 활용하여 모든 tf 값들을 lf_weighting 값으로 변경해주었다.
for doc in dic.values():
doc_term = dict(Counter(okt.nouns(doc[0])))
tf_raw = list(doc_term.values())
tf = list(map(lf_weighting, tf_raw))
4. 단어의 idf 구하기
문서에 포함되는 단어들이 문서를 구분하는 데 얼마나 영향력이 있는지 판별하기 위해 idf를 계산해야 한다.
아래 내용은 내 강의 노트의 일부분을 가져왔다.
📌 idf weight
-
$df_{term}$는 term를 포함하는 문서의 빈도이다. -
우리는 df가 작은 term의 점수를 더 높게 주고 싶기 때문에, df을 뒤집어서 분모로 사용하자.
-
idf(inverse document frequency)
$idf_t=log_{10}(N/df_t)$-
N = 전체 document 수
-
idf값을 완화 시키기 위해 log를 취해준다.
log의 base가 꼭 10일 필요는 없다.
-
우선 lf_weight와 마찬가지로 idf를 계산하기 위한 함수를 선언해주었다.
def idf_cal(x):
return round(math.log(N / x, 2), 4)
단어의 idf를 구하기 위해, 단어가 전체 문서 중 몇 개의 문서에 포함 되는지 알아야 하는데, 해당 부분은 다음과 같은 과정으로 수행됐다.
-
corpus 전체 내용에서 okt를 통해 단어를 추출하고, 중복 단어를 제거하여 단어 목록을 만든다.
words = [] for doc in dic.values(): doc_term = dict(Counter(okt.nouns(doc[0]))) words.extend(list(doc_term)) df = {} words = set(words) # print(words) -
단어 목록에서 단어마다 몇 개의 문서에 포함 되는지 확인한다.
for w in words: count = 0 for doc in dic.values(): if w in doc[0]: count += 1 df[w] = count df = dict(sorted(df.items(), key=lambda x: x[1], reverse=True)) -
단어마다 포함되는 문서의 개수를 dictionary에 저장한 후, 해당 값을 idf로 변환한다.
df_raw = list(df.values()) idf = list(map(idf_cal, df_raw)) -
나중에 단어의 idf를 탐색하기 위해 idf list를 dictionary 형태{key: word, value: idf}로 저장한다.
i = 0 for key in df: df[key] = idf[i] i += 1 word_idf = dict(sorted(df.items(), key=lambda x: x[1], reverse=True))
5. 문서의 tf-idf Weight 계산하기.
📌 tf-idf weighting
-
term의 tf-idf 가중치는 tf 가중치와 idf 가중치의 곱이다.
$$ W_{t,d}=(1+log_{10}tf_{t,d}) \times log_{10}(N/df_t) $$ -
IR에서 가장 핵심적인 가중치 공식이다.
tf.idf나 tf x idf라고 부르기도 한다.
-
가중치는 collection에서 term의 발생 빈도에 따라 증가한다.
-
가중치는 컬렉션 내에 term이 희귀할수록 증가한다.
이제 거의 다 왔다. 그저 문서 각각에 포함된 단어별 tf 값에, 해당 단어를 word-idf 사전에 검색하여 값을 곱해주기만 하면 된다.
for doc in dic.values():
for word in doc[1].keys():
doc[1][word] = round(word_idf[word] * doc[1][word], 4)
# print(doc[1])
이제 인덱싱은 완료되었으니, Query를 입력 받고 score를 계산하기만 하면 된다.
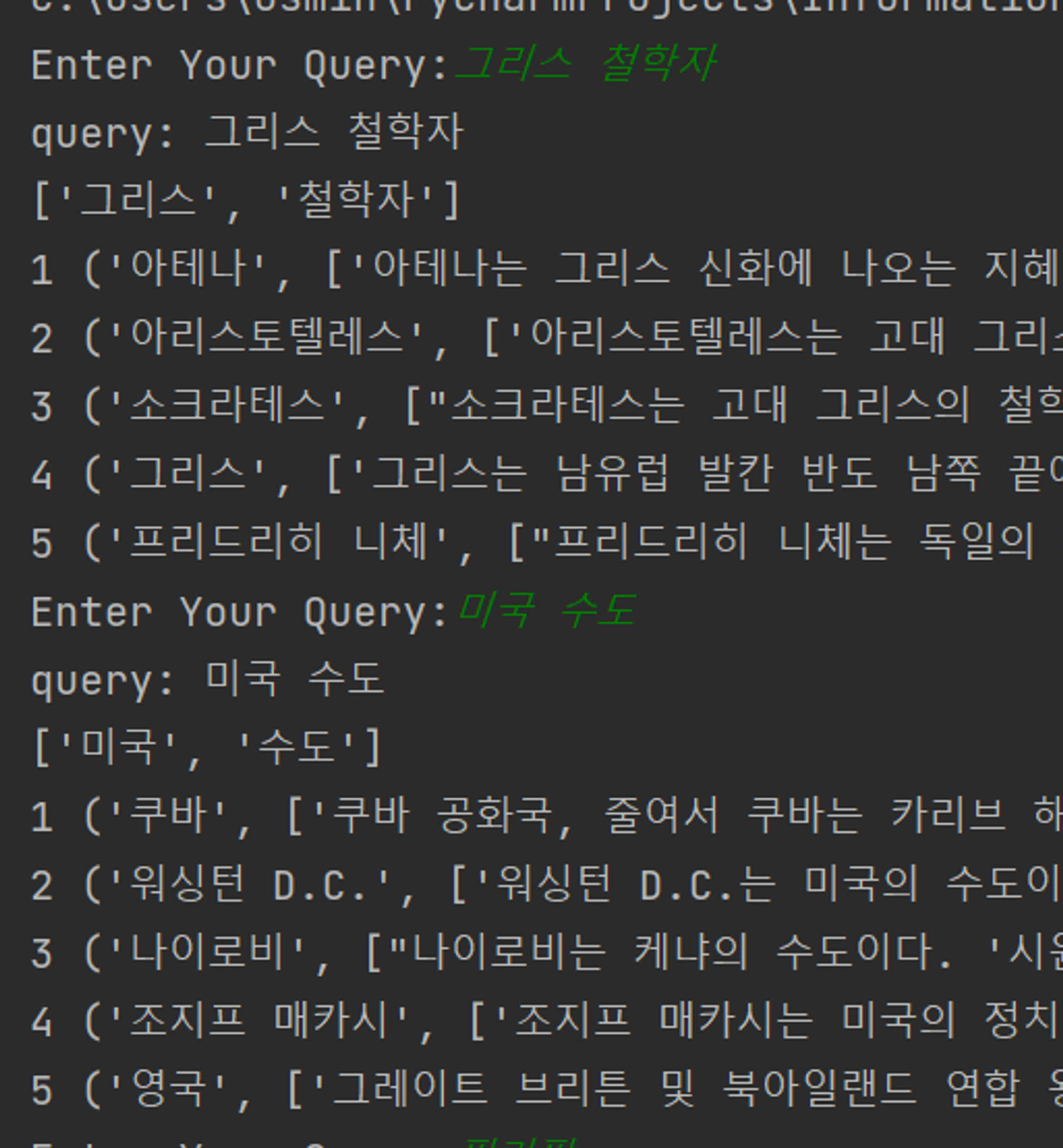
6. query 입력 창 구현하기
while (1):
query = input("Enter Your Query:")
print("query: " + query)
query_term = okt.nouns(query)
print(query_term)
7. Score 계산하기
$$
\operatorname{Score}(q, d)=\sum_{t \in q\urcorner d} t f . i d f_{t, d}
$$
위 수식은 q(query)와 d(document)에서 공통되는 term을 가진 document의 score만 계산한다는 의미이다.
score 계산은 위 수식처럼, 쿼리에 포함되는 단어 중 문서에 포함된 단어의 tf-idf를 더하면 된다.
for doc in dic.values():
score = 0
for q in query_term:
for word in doc[1].keys():
if word == q:
score += doc[1][word]
if len(doc) == 2:
doc.append(score)
else:
doc[2] = score
8. 문서의 Score가 높은 순서대로 보여주기
fin_dic = sorted(dic.items(), key=lambda x: x[1][2], reverse=True)
i = 0
for result in fin_dic:
if i >= OUT:
break
i += 1
if result[1][2]:
print(i, result)
else:
print(i, "검색 결과가 없습니다.")