Background
이때까지 우리의 쿼리는 모두 Boolean을 활용한 것이었다.
Boolean은 자신들의 원하는 검색결과를 정확하게 아는 전문가들이 사용하기에 좋다.
또한 많은 정보를 탐색하는 전문가들에게 유용하다.
하지만 대부분의 사람들이 편하게 사용하기엔 적절하지 않다.
대부분의 유저들은 boolean 쿼리를 작성하지 못한다.
사용자들은 그렇게 많은 결과물이 필요하지 않다.
대부분 Boolean query는 문서가 너무 많이 나오거나, 너무 적게 나온다.
Query 1: “standard user dlink 650” → 200,000 hits
Query 2: “standard user dlink 650 no card found”: 0 hits
AND는 너무 적게 나오고, OR은 너무 많이 나온다.
심지어 순서도 없이 뒤죽박죽 나온다.
-
Quiz 1: Search results
- X AND Y에대해 구글 검색할 때, 총 2000개의 결과가 리턴
- X AND Y AND Z에대해 구글 검색할 때, 총 3500개의 결과가 리턴
왜 2번째 쿼리가 더 많은 결과를 리턴하는가?
Ranked Retreival Models
AND, OR 이렇게 검색하지 않고, 사람에게 말하듯이 검색하고자 한다.
즉, 쿼리 표현식을 만족하는 문서의 집합이 아닌, 시스템이 쿼리에 대한 컬렉션에 대한 상위 랭킹의 문서를 리턴한다.
- free text query: 쿼리 언어의 precise query(연산자나 표현) 보다는 사용자의 쿼리는 한단어 이상의 자연어가 입력된다.
- 실전에서는 보통 ranked retreival이 free text 쿼리랑 조합된다.
이 때, 랭킹 알고리즘 품질을 좋게 유지해야 한다.
랭킹을 매기는 문서의 양을 줄이는 것은 품질면에서는 큰 이슈가 아니다.
구글 검색의 클릭률을 보면 대부분 1페이지의 10개의 검색결과의 클릭률이 94%이다.
유저는 2페이지로 이동할 가능성 조차 낮다.
Ranked Retreival의 기준 점수 매기기
가장 그럴듯한 문서 순서대로 리턴해주고 싶은데, 쿼리마다 문서의 랭킹을 어떻게 정할 수 있을까?
각 문서가 쿼리에 매칭되는 정도를 0과 1 사이의 값으로 점수를 매긴다.
해당 점수는 query time에 계산된다.
계산이 오래 걸려선 안된다.
Query-document matching scores
쿼리-문서 쌍에 대해 점수를 할당하는 방법
복잡한 것을 배우기 전에 term 한개짜리 쿼리부터 시작해보자.
- 만약 query term이 문서에 없다면 0점
- query term의 출현 빈도가 클수록 높은 점수를 할당
- 앞으로 이 방식에 대한 몇가지 대안을 살펴볼 예정
Jaccard coefficient
앞에서 단어간 유사도를 확인할 때 사용했었다.
- 일반적으로 쓰여지는 A와 B집합의 관계는 아래와 같이 나타낸다.
- jaccard(A,B)=
$|A∩B||A∪B|$ - jaccard(A,A)=1
- jaccard(A,B)=0 if
$A∩B=0$
- jaccard(A,B)=
- A와 B가 같은 크기일 필요는 없다. 문서의 term 개수보다 query term이 적은 것이 당연하다.
- 항상 0~1 값을 가진다.
쿼리-문서 match 점수에서 Jaccard coefficient는 어떻게 계산할까?
Query: ides of march 일 때
- Document 1: caesar died in march ⇒ 1 / 3 + 4 - 1
- Document 2: the long march ⇒ 1 / 3 + 3 - 1
doc1 : $1\over6$ doc2 : $1\over5$ 즉 doc2가 점수가 조금 더 높다.
Jaccard coefficient의 문제점
-
term frequency를 고려하지 않는다.
문서 안에서 동일한 term이 몇 번 발생했는지는 관심이 없다.
하지만 이 값은 중요하다.
-
term frequency(
$tf_{term}$)어떤 document 안에서 해당 term이 나타난 횟수
-
document frequency(
$df_{term}$)어떤 term이 나타나는 document의 개수
-
collection frequency(
$cf_{term}$)collection 전체에서 어떤 term이 나타난 횟수
-
-
Scoring의 목적이 query와 document 사이의 관계이다.
collection에서 드물게 나타나는 term은 흔한 term보다 문서를 특정하기에 훨씬 더 유용하다.
하지만 Jaccard는 frequency를 고려하지 않기 때문에 이 정보를 고려하지 않는다.
-
길이를 normalize 할 더 세련된 방법이 필요하다.
문서의 길이가 긴 경우 동일한 단어가 더 많이 출몰할 것이다.
이를 문서의 길이가 짧은 경우의 단어 출몰 횟수랑 비교하기 위해 정규화할 필요가 있다.
-
나중에 이 수식을 사용한다.
$|A∩B||A∪B|$
Recall: Binary term-document incidence matrix
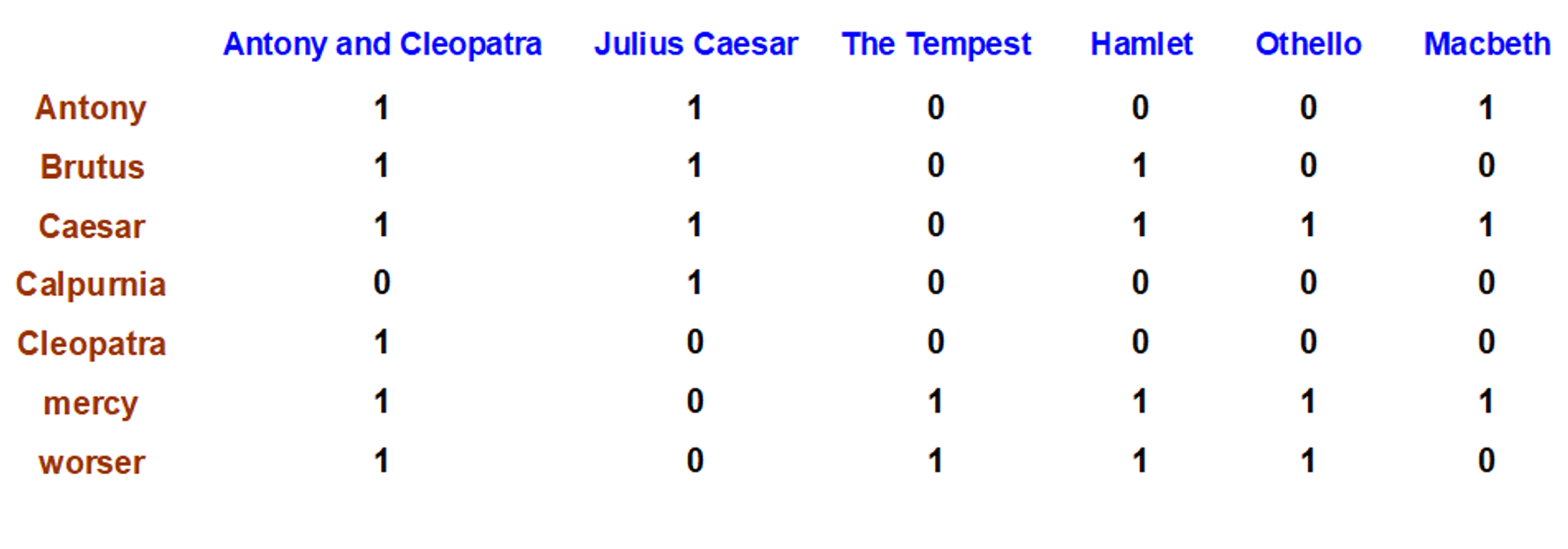
예를 들어 antony and brutus and not(calpurnia)라면
$110001$$110100$$101111 -> 100000$
위 비트와이즈 연산을 통해 “Antony and Cleopatra”가 만족하는 소설책임을 찾을 수 있다.
-
각 문서를 바이너리 벡터로 표시한다.
$vector ∈ \{0,1\}^{V}$
Term-document count matrices
-
frequency를 고려하기 위해 0/1 벡터 대신에 횟수를 벡터화한다.
-
문서에 term이 등장한 횟수를 고려함
각 문서는 자연수를 담은 count vector로 표시
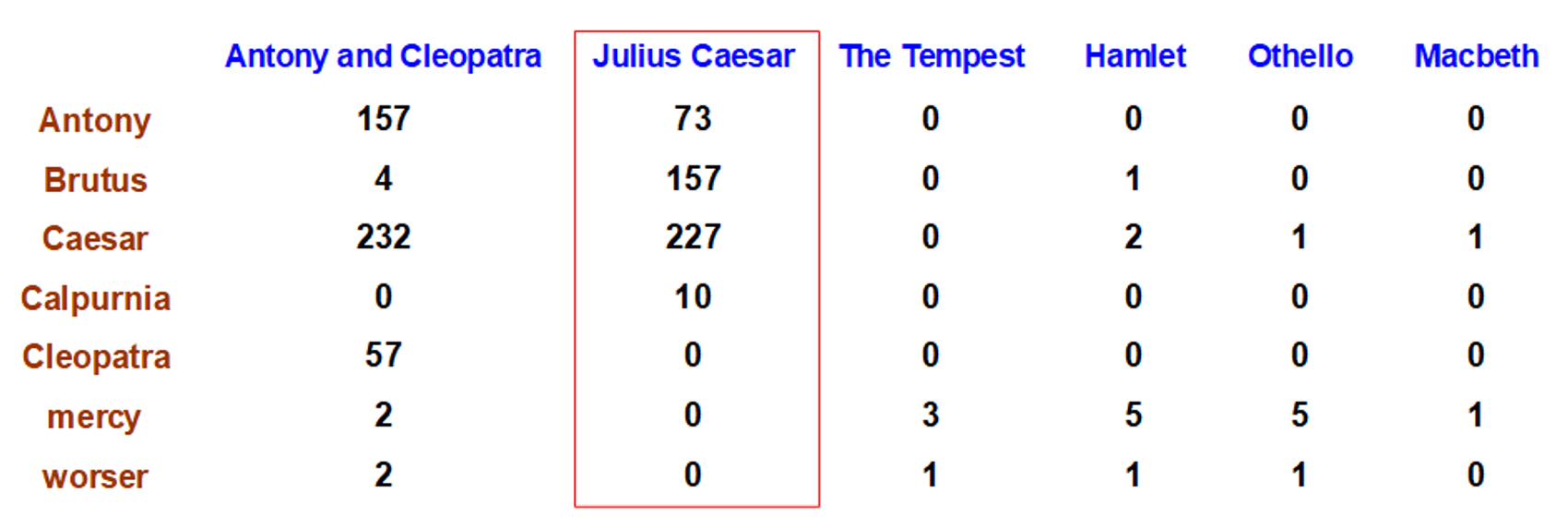
문서에서 단어의 등장횟수가 많은 것들이 중요하다.
Bag of words model
-
벡터 표현은 문서안의 단어의 순서를 고려하지 않는다.
- John is quicker than Mary
- Mary is quicker than John
위의 두 문장은 다른 뜻이지만 같은 벡터를 가지게 된다.
-
이를 BOW(bag of words) 모델이라고 부른다.
-
위의 두 문장의 차이를 구별할 수 있는 positional index에 비해 BOW는 후퇴한 것처럼 보인다.
하지만 positional index는 presentation을 판별하기 위해 사용됐던 것이다.
나중에 positional index가 다시 언급된다.
TF: Term frequency
term frequency($tf_{t,d}$): 문서 d에서 term t가 발생한 빈도
tf를 query-document가 얼마나 일치하는지 계산하기 위해 쓰고 싶다.
raw tf 값은 활용하기 불편하다.
tf 10인 문서가 tf 1인 문서보다 더 연관도가 높다.
하지만 숫자의 크기가 해당 문서가 10배 더 유의미하다는 의미는 아니다.
문서의 연관성은 tf의 수에 따라 비례적으로 증가하지는 않는다.
게다가, 단어의 빈도가 0개인 문서와 1개인 문서의 차이는 매우 크지만,
100개인 문서와 101개인 문서의 차이는 아주 작다.
따라서 단어의 개수에 따라 달라지는 영향력을 표현하기 위해, 단어의 빈도에 log를 취한다.
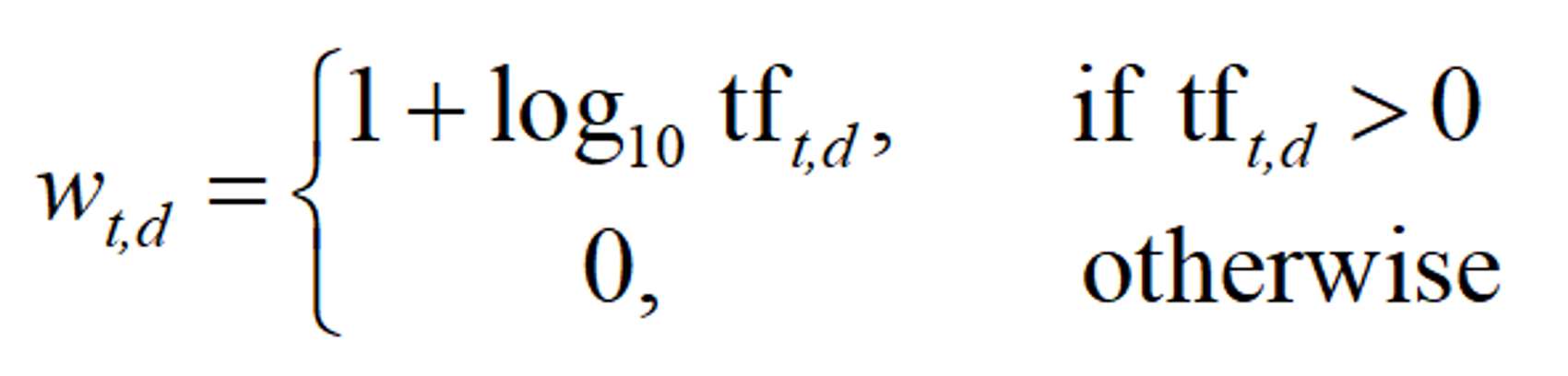
이 때, 단어가 하나 있는 것과 아예 없는 것의 차이는 훨씬 크기 때문에, 0과 1은 따로 구분한다.
$$
\tt score = ∑_{t∈q∩d}(1+log tf_{t,d})
$$
문서의 점수를 계산하기 위해선, query와 document에서 공통으로 나타나는 단어의 빈도를 log로 계산하면 된다.
- 문서에서 query term이 하나도 발견되지 않으면 점수는 0이다.
- ex
term frequency weight 0 0 1 1 2 1.3 10 2 1000 4
DF: Document Frequency
-
희귀한 term은 흔한 term 대비 더 유용하다.
stop word와 같은 것들은 문서를 구별짓는데 도움이 되지 않는다.
arachnocentric이 문서를 구별짓는데 훨씬 많은 도움이 된다.
-
이렇게 희귀한 term을 포함한 문서는 쿼리 term에 매우 연관도가 높을 것이다.
희귀한 arachnocentric같은 term에 가중치를 부여해야 한다.
요약하면, Document frequency가 작은 단어일수록 유용하고, term frequency가 큰 단어일수록 문서를 특정짓는데 유용하다.
효과적인 검색을 위해 document frequency($df$)에 대한 정보도 활용해야 한다.
-
모든 document에서 나타나는 term들은 문서를 검색하는데 도움이 크게 되지 않는다.
-
컬렉션 내에서 흔한 term을 생각해보자. (ex: high, increase, line)
물론 이러한 term을 포함하는 문서가 그러지 않은 문서보다는 연관있을 가능성이 높다.
하지만 확실한 연관도의 척도가 될 수는 없다.
term frequency가 높은 단어들에게 높은 가중치를 부여해야 한다.
document frecuency가 낮은 단어들에게 높은 가중치를 부여해야 한다.
IDF: Inverse Document Frequency
$$
\tt idf_t=log_{10}(N/df_t)
$$
- N = 전체 document 수
df가 작은 term의 점수를 더 높게 주기 위해 df를 뒤집어서 분모로 사용한다.
idf값을 완화시키기 위해 log를 취해준다.
log의 base가 꼭 10일 필요는 없다.
-
ex) N = 1 million
N(문서의 개수) = 1,000,000이고,
$idf_t=log_{10}(N/df_t)$인 경우term df_t idf_t calpurnia 1 6 animal 100 4 sunday 1,000 3 fly 10,000 2 under 100,000 1 the 1,000,000 0 - the처럼 모든 document에서 나타나는 단어는 가중치가 0이 되어버린다.
- 전체 collection에 존재하는 term마다 고유한 idf 값이 존재한다.
- 쉽게 이해하자면 idf를 적용하면 calpurnia는 promoting하고 the는 demoting한다.
-
idf는 one term 쿼리에 있어서는 랭킹에 변화가 없다.
-
어차피 가중치를 구할 때 모든 document에 항상 같은 값이 곱해지게 된다.
-
idf는 적어도 2개의 term 이상에 대해 효과가 있다.
“capricious person”라는 쿼리가 있으면 idf 가중치는 capricious 라는 희귀한 단어에 person 이라는 흔한 단어 보다 상대적으로 높은 가중치를 부여하게 된다.
ex) query : iphone box
-
-
CF vs. DF
-
t에 대한 Collection Frequency는 전체 컬렉션 내에서 t가 발생한 빈도수를 집계한다.
여러번 등장한 것을 모두 센다.
-
ex
두 단어의 collection frequency가 비슷하지만, insurance의 document frequency에 비해 try의 document frequency가 훨씬 크다.
그러므로 insurance가 더 높은 가중치를 받아야 한다.
-
TF-IDF
문서에 등장한 단어들의 중요도를 나타내는 값
단어마다 TF-IDF 값이 계산된다.
IR에서 가장 핵심적인 가중치 공식
$$
\tt W_{t,d}=(1+log_{10}tf_{t,d}) \times log_{10}(N/df_t)
$$
term의 tf-idf 가중치는 tf 가중치와 idf 가중치의 곱이다.
tf.idf나 tf x idf라고 부르기도 한다.
가중치는 collection에서 term의 발생빈도에 따라 증가한다.
가중치는 컬렉션 내에 term이 희귀할수록 증가한다.
쿼리에 대한 문서의 Score 계산
$$
\tt Score(q,d)=∑_{t∈q∩d}tf.idf_{t,d}
$$
위 수식은 q(query)와 d(document)에서 공통되는 term을 가진 document의 score만 계산한다는 의미이다.
문서들의 Score을 계산할 때 다양한 옵션이 존재한다.
-
tf를 계산하는 방법
- log 적용 여부
- log의 base 크기
-
쿼리를 구성하는 term에 가중치 부여 여부
가중치 부여 없이, query도 하나의 document처럼 처리하는 방법도 있다.
query는 document의 한 종류다.
문서를 나타내는 방법
문서들을 tf-idf 가중치 행렬로 나타낸다.
| Antony and Cleopatra | Julius Caesar | The Tempest | Hamlet | Othello | Macbeth | ||
|---|---|---|---|---|---|---|---|
| d1 | d2 | d3 | d4 | d5 | d6 | ||
| Antony | t1 | 5.25 | 3.18 | 0 | 0 | 0 | 0.35 |
| Brutus | t2 | 1.21 | 6.1 | 0 | 1 | 0 | 0 |
| Caesar | t3 | 8.59 | 2.54 | 0 | 1.51 | 0.25 | 0 |
| Calpurnia | t4 | 0 | 1.54 | 0 | 0 | 0 | 0 |
| Cleopatra | t5 | 2.85 | 0 | 0 | 0 | 0 | 0 |
| Mercy | t6 | 1.51 | 0 | 1.9 | 0.12 | 5.25 | 0.88 |
| worser | t7 | 1.37 | 0 | 0.11 | 4.15 | 0.25 | 1.95 |
각 문서는 tf-idf 가중치의 실수값 벡터로 표현된다.
즉, 각 문서를 구성하는 Term들을 tf-idf 값으로 전환하여 문서를 벡터화한다.
tf-idf 가중치 행렬 $∈R^{\|V\|}$
$V$는 문서에 포함된 단어의 개수를 의미한다.
결국 $\|V\|$ 차원의 벡터 공간을 가지게 된다.
term은 공간의 차원이 된다.
문서는 공간에서의 벡터(점)이라고 이해할 수 있다.
쿼리도 문서와 같은 크기로 들어가야 한다.
쿼리도 문서로 취급하여 벡터로 표현한다.
하지만 만약 이 개념을 웹 검색엔진에 적용한다면 차원이 수억개가 된다.
이는 매우 sparse한 벡터이고 대부분의 값은 0일 것이기에, 다른 방법이 필요하다.
-
공간에서 쿼리 벡터(문서)의 유사도(proximity)에 대해 랭킹을 매긴다.
score(q,d1), score(q,d2)…는 벡터공간 상에서 문서벡터가 쿼리벡터와 얼마나 흡사한지를 판별한다.
proximity ≈ inverse of distance
즉, 거리가 가까울수록 문서와 쿼리가 비슷하다
boolean 모델에서 벗어나기 위해 이 작업을 수행한다.
-
대신에 더 연관있는 문서에 더 높은 랭크를 부여한다.
TF-IDF의 다양한 선택지
tf-idf의 가중치 알고리즘은 선택의 폭이 다양하다.
가장 많이 쓰이는 것은 붉은 색 표시가 되어있다.
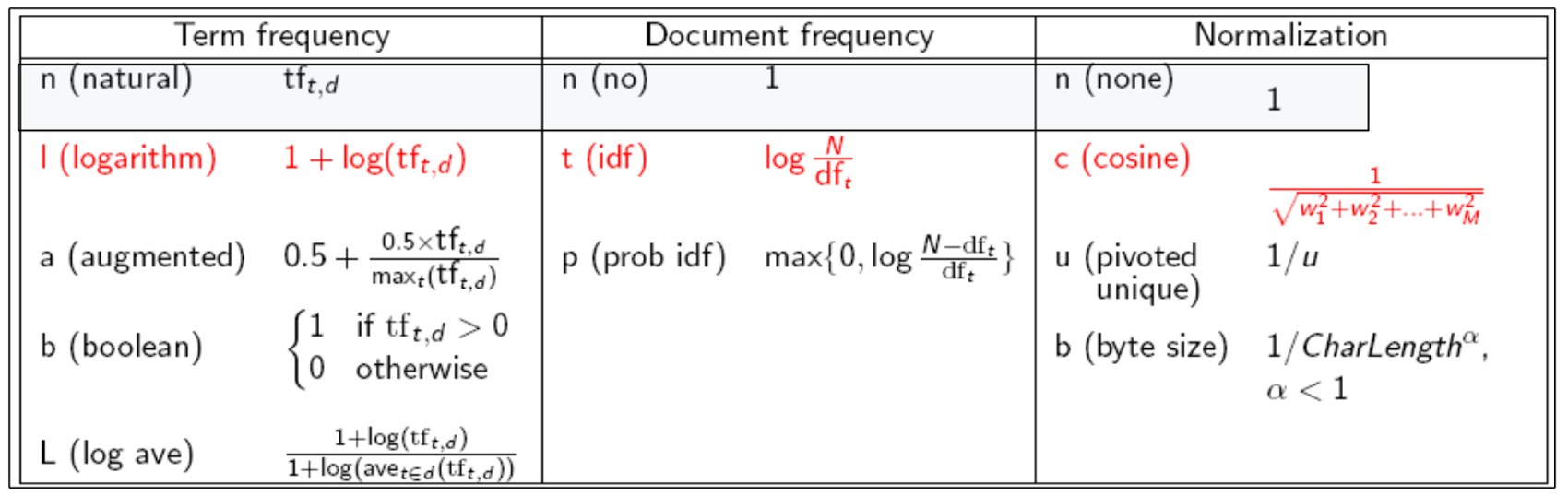
-
많은 검색 엔진들이 쿼리나 문서에 대해 다양한 가중치 부여방식을 허용한다.
-
표기법
ddd.qqq
앞의 3글자: 문서에 대한 알고리즘
뒤의 3글자: 쿼리에 대한 알고리즘
ex) lnc.ltc
document → lnc
- logarithmic tf
- no idf
- cosine normalization
query → ltc
- logarithmic tf
- (t) ⇒ idf
- cosine normalization
-
매우 표준적인 가중치 부여 방식으로 lnc.ltc가 있다.
quiz: document에 no idf를 적용하는것이 나쁜 아이디어인가?
ltc.lnc가 더 일반적으로 보인다.
ex — lnc.ltc
- 문서: car insurance auto insurance
- 쿼리: best car insurance
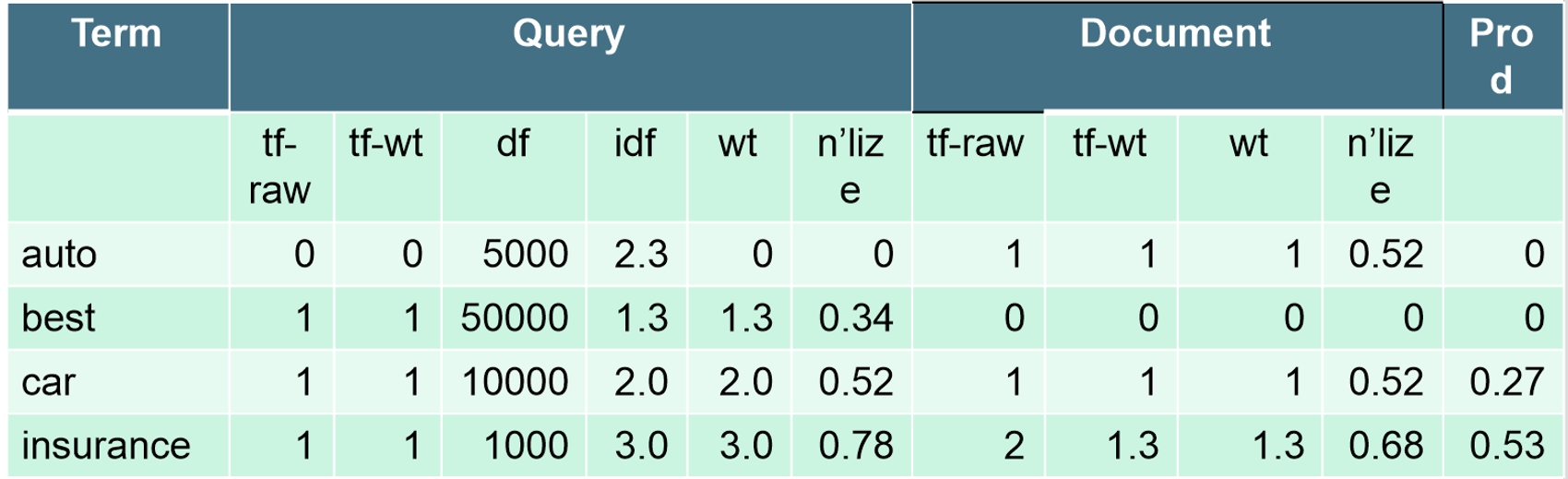
tf-raw: term의 발생횟수
tf-wt: $1+log(tf_{t,d})$. 즉, term의 발생빈도를 가중치로 바꾼 것.
idf: $log{N\over df_t}$
wt: tf-wt * idf : $(1+log(tf_{t,d}))\times log{N\over df_t}$
n’lize: 문서 길이(wt 제곱 총합의 루트) 로 wt를 나눈 것
문서의 길이: $\sqrt {1^2+0^2+1^2+1.3^2} \simeq 1.92$
실제 코사인 유사도는 내적값의 합으로 auto에 대한 내적값 0, best에 대한 내적값 0, car에 대한 내적값 0.27(0.52 * 0.52)과 insurance에 대한 내적값 0.53(0.78 * 0.68)을 더한 0.8이다.
- quiz: 문서의 수, N은 몇일까?