간단 요약
autograd 연산을 지원하는 다차원 배열
tensor에 대한 미분값을 가진다.
- reshape보다 view를 쓰는 것이 좋다.
- squeeze와 unsqueeze의 차이
- mm, dot, matmul 차이
신경망의 가중치(매개변수)를 텐서로 표현한다.
다차원 Arrays를 표현하는 PyTorch 클래스
numpy의 ndarray와 호환된다.
TensorFlow의 Tensor와도 동일
Tensor을 생성하는 함수도 거의 동일
-
numpy — ndarray
import numpy as np n_array = np.arange(10).reshape(2,5) print(n_array) print("n_dim :", n_array.ndim, "shape :", n_array.shape) -
pytorch — tensor
import torch t_array = torch.FloatTensor(n_array) print(t_array) print("n_dim :", t_array.ndim, "shape :", t_array.shape)
list나 ndarray를 Tensor로 변환할 수 있다.
데이터 타입은 numpy와 동일하다.
GPU에 올려 사용이 가능하다.
x_data.device
# device(type='cpu')
if torch.cuda.is_available():
x_data_cuda = x_data.to('cuda')
x_data_cuda.device
# device(type='cuda', index=0)
view, squeeze, unsqueeze 등으로 tensor 조정이 가능하다.
view: reshape와 동일하게 tensor의 shape를 변환한다.
-
view와 reshape의 차이: contiguity(접근) 보장 여부
view의 경우 클래스로의 접근을 계속 보장해주지만, reshape는 접근을 보장해주지 않는다.
만약 접근을 보장할 수 없는 경우 copy를 해버린다.
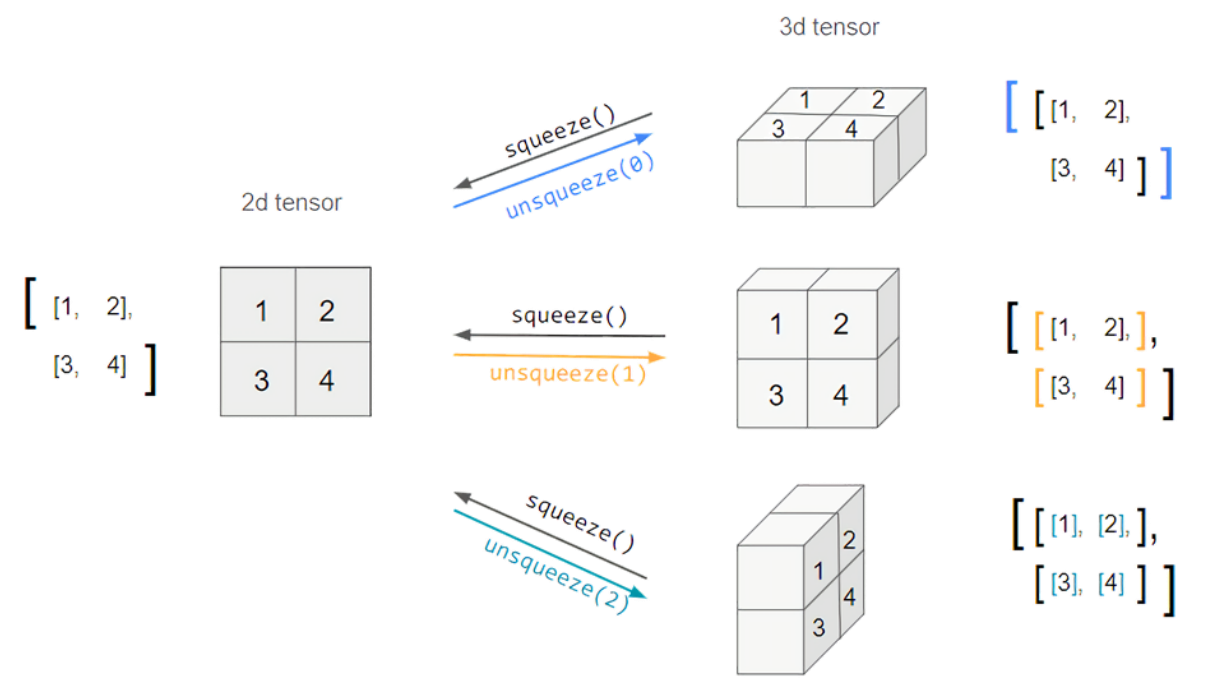
squeeze: 차원의 개수가 1인 차원을 삭제한다. (압축)
import torch
x = torch.rand(1, 1, 20, 128)
x = x.squeeze() # [1, 1, 20, 128] -> [20, 128]
x2 = torch.rand(1, 1, 20, 128)
x2 = x2.squeeze(dim=1) # [1, 1, 20, 128] -> [1, 20, 128]
unsqueeze: 차원의 개수가 1인 차원을 추가한다.
추가할 위치를 지정해주어야 한다.
import torch
x = torch.rand(3, 20, 128)
x = x.unsqueeze(dim=1) #[3, 20, 128] -> [3, 1, 20, 128]
다른 기본적인 연산은 Tensor와 Numpy가 거의 동일하다.
dot, mm, matmul 차이
dot : 내적 연산.
mm : 행렬 곱셈 (벡터 연산 지원 x).
행렬곱셈 연산이 Tensor에서는 dot 대신 mm(matrix multiplication)으로 표기된다.
matmul : 알아서 broadcasting을 지원해준다.
쉽게 연산해준다는 장점이 있지만, 오히려 결과를 헷갈리게 만드는 단점이 있다.
Tensor의 구조
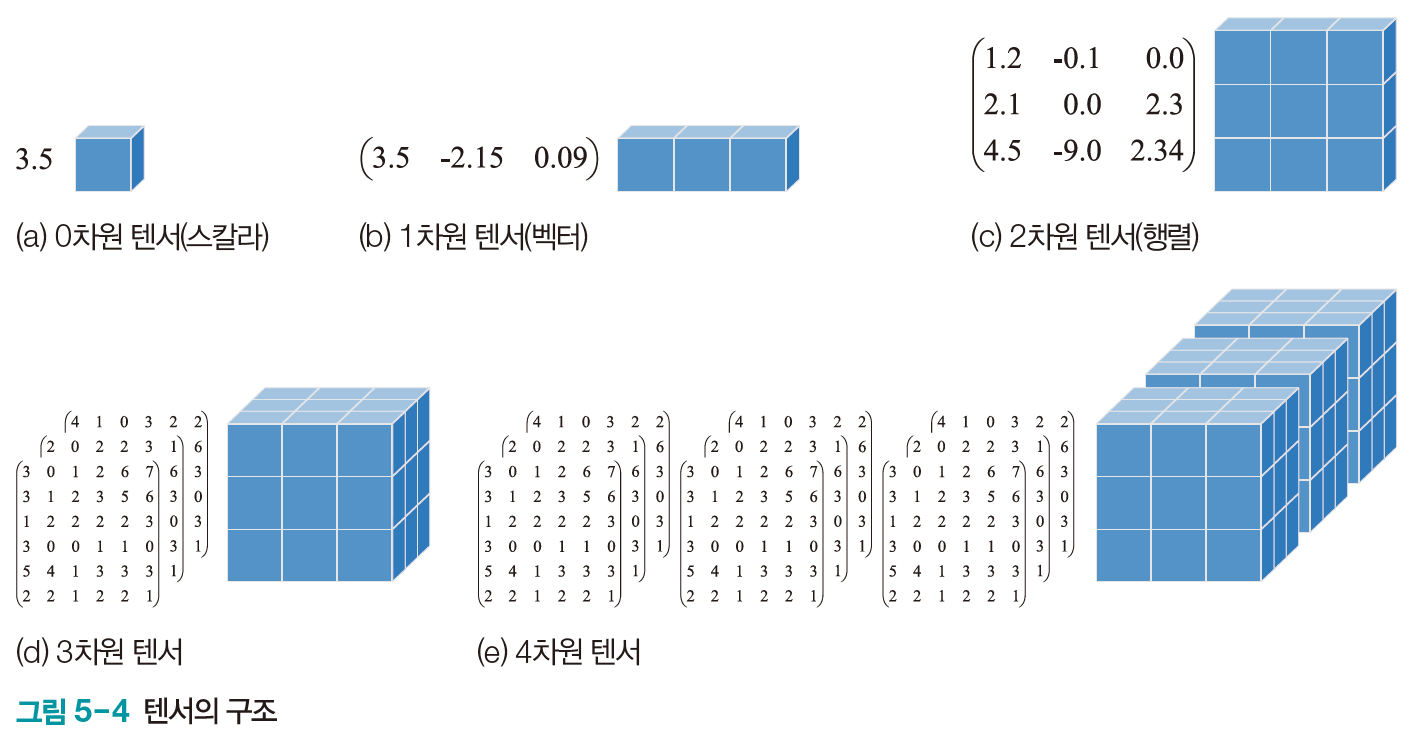
- 1차원: iris 샘플 하나
- 2차원: iris 샘플 여러 개, 명암 영상 한 장
- 3차원: 명암 영상 여러 장, 컬러 영상 한 장
- 4차원: 컬러 영상 여러 장, 컬러 동영상 하나
- 5차원: 컬러 동영상 여러 개