SG를 이진 분류 문제로 바꾼 모델
Negative Sampling
주변 단어가 아닌 단어를 Label 0으로 Sample에 포함시키는 것

Negative Sampling의 개수는 하이퍼파라미터에 해당한다.
- 학습 데이터가 적은 경우 5-20, 충분히 큰 경우 2-5가 적당하다.
- positive sample 하나당 k개 샘플링
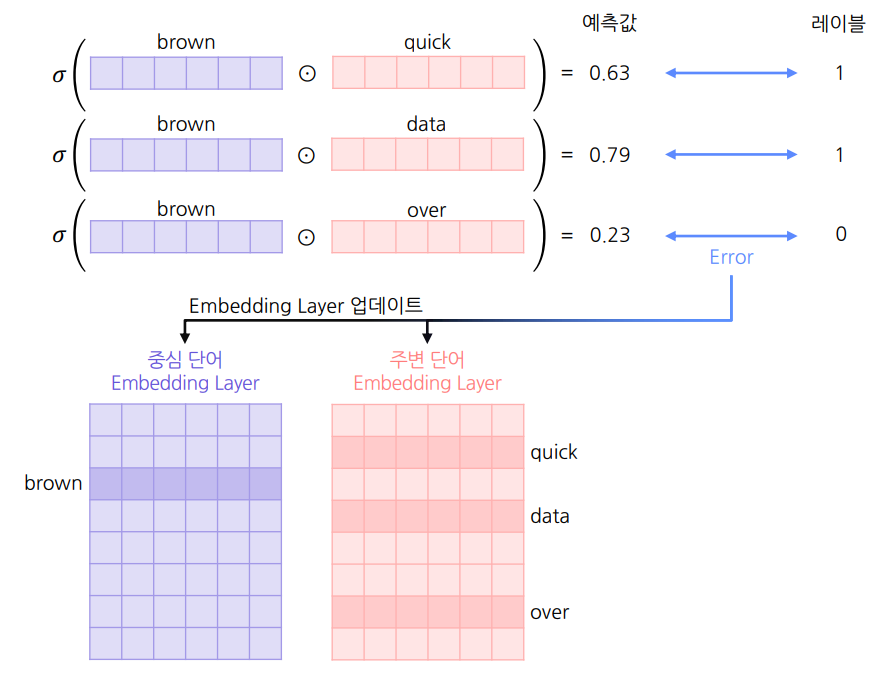
중심 단어와 주변 단어가 각각 임베딩 벡터를 따로 가진다.
만약 input/output 혹은 word/context representation을 동일한 값으로 사용한다고 하면,
특정 단어, 가령 “dog"에 대해 P(dog|dog)가 현실적으로는 불가하지만 (한 문장에 “dog dog"를 연속으로 쓸 일은 없으니..) word2vec 모델 상으로는 높은 값을 뱉어낼 수 밖에 없습니다.
이러한 언어의 특수성을 통해 유추해보건대, 문장 내에서는 하나의 단어가 중심 단어의 역할을 할 때와 주변(맥락) 단어의 역할을 할 때에 서로 다른 표현력(representation power)을 가지는 것이 아닐까 싶습니다.
해당 stackoverflow 답변에서 혹자는 “‘문장 내 단어 간 유사도/거리’를 측정할 때 하나의 벡터 공간만을 사용하게 되면 결국 그냥 두 단어 임베딩 간의 유사도/거리를 측정하는 것과 별반 다르지 않기 때문에 문장의 문맥을 담을 수 없다”는 식으로 설명하는데, 이 또한 비슷한 맥락이라고 볼 수 있을 것 같습니다.
학습 과정
-
중심 단어를 기준으로 주변 단어들과의 내적 연산 수행
-
실수 내적값에 sigmoid을 취하여 예측값을 구한다.
-
예측값과 레이블(0,1)의 오차를 구한다.
-
역전파(backpropagation)를 통해 각 임베딩이 갱신되며 모델이 수렴한다.
-
이 때, 최종적으로 생성된 워드 임베딩이 2개이므로 선택적으로 하나만 사용하거나 평균내어 사용한다.