Naver BoostCamp AI Tech에서 학습한 내용을 재구성했습니다.
해당 게시글은 지속적으로 업데이트할 예정입니다.
노션에 정리했던 내용을 복습하며 블로그에 조금씩 업로드하고 있습니다.
추천 시스템
추천 시스템 평가 패러다임
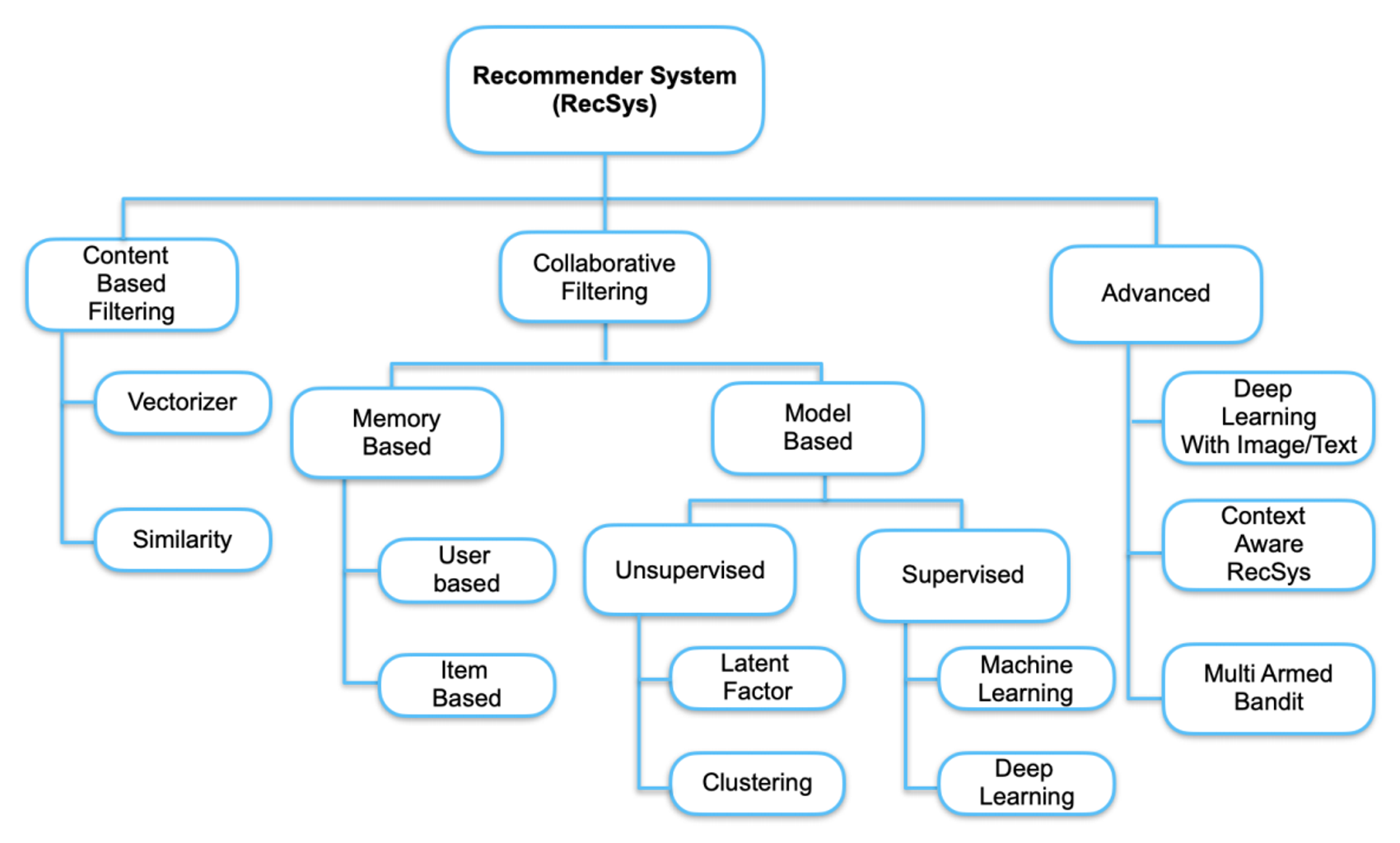
Rule Base
CBF: Content Based Filtering
1. Vectorizer — 아이템 특성을 벡터 형태로 어떻게 표현하는가
2. Similarity — 특성화된 아이템이 서로 얼마나 비슷한가
CF: Collaborative Filtering(협업 필터링)
-
NBCF: Neighborhood-based CF(이웃 기반 협업 필터링)
-
MBCF: Model based Collaborative Filtering(모델 기반 협업 필터링)
ML based CF
DL based CF
DL based CF의 장점
-
Nonlinear Transformation
-
data의 non-linearity를 효과적으로 나타낼 수 있다.
-
복잡한 user-item interaction pattern을 효과적으로 모델링
user의 선호도 예측 용이
-
-
Representation Learning
- 사람이 직접 feature design하지 않아도 된다.
- 텍스트, 이미지, 오디오 등 다양한 종류의 정보를 추천 시스템에 활용할 수 있다.
- 과거 아이템의 이미지를 활용하여 새로운 아이템에 대한 특징 추출 가능
- 사용자가 남긴 텍스트를 활용하여 취향에 대한 특징 추출 가능
- 새로운 아이템이나 인기 없는 아이템도 추천이 가능
- 사용자에게 아이템을 왜 추천하는 이유에 대한 설명력이 증가
- 다양한 맥락 정보를 함께 활용하기 때문에 보다 정교한 추천이 가능
-
Sequence Modeling
- DNN은 자연어처리, 음성 신호 처리 등 sequential modeling task에서 성공적으로 적용된다.
- 추천 시스템에서 next-item prediction, session-based recommendation등에 사용된다.
-
Various Architectures
- CNN, RNN 등 비정형 데이터 특징 추출에 특화된 구조 활용이 가능하다.
-
Flexibility
- Tensorflow, PyTorch 등 다양한 DL 프레임워크 오픈
- 추천시스템 모델링 flexibility가 높으며 더 효율적으로 서빙할 수 있다.
- end-to-end 구조로써 Domain adaptation,Generative modeling등의 응용 모델 활용이 가능하다.
단점
- Interpretability → Black Box
- Data Requirement → 많은 양의 데이터 필요
- Extensive Hyperparameter Tuning → 많은 시간 소요
추천에서는 DL이 ML을 압도하지는 않는다.
추천을 수행할 때 Latency가 중요하기 때문에, 너무 복잡한 모델은 사용하지 못한다.
MLP: Multilayer Perceptron(다층 퍼셉트론) 계열 모델
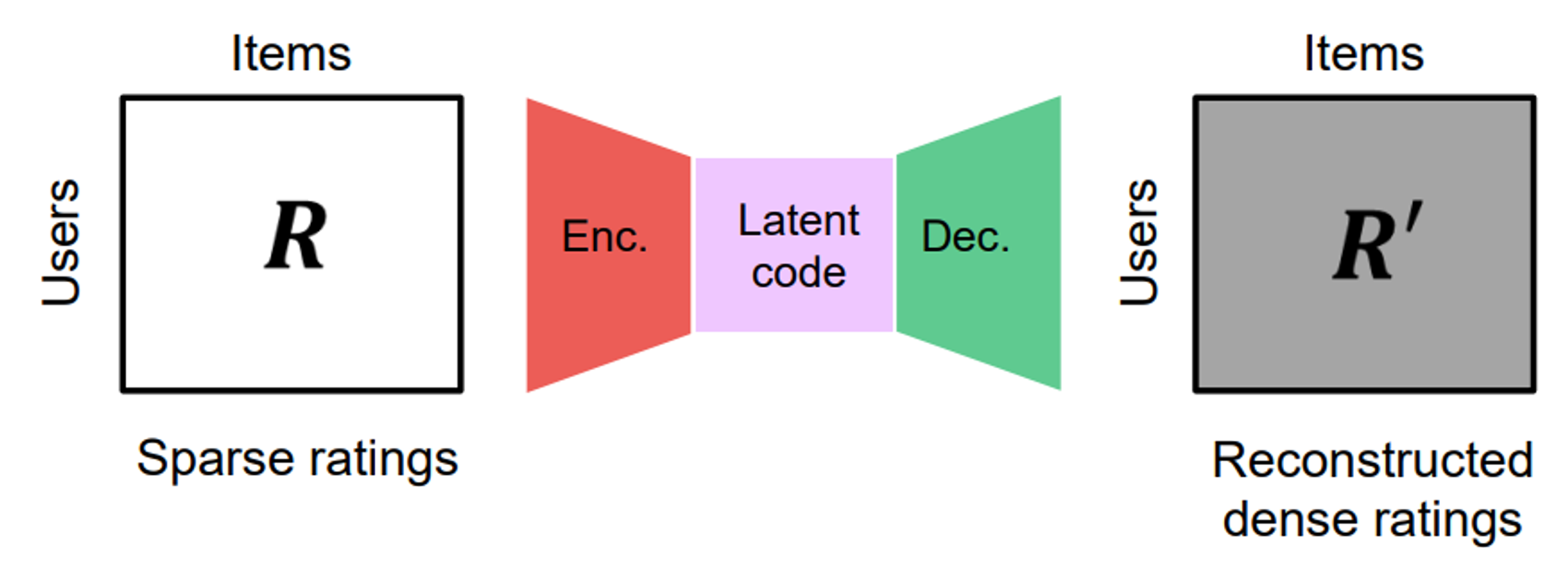
AE: Autoencoder(오토인코더) 계열 모델
입력값 (rating)을 reconstruction (decoding) 할 수 있게끔 학습함으로써 rating이 가지고 있는 잠재적인 패턴이 latent factor(information bottleneck)에 암호화 (encoding)된다.
GNN: Graph Neural Network 계열 모델
GCN: Graph Convolution Network
CNN: Convolutional Neural Network(컨볼루션 신경망) 계열 모델
RNN:Recurrent Neural Network(순환신경망) 계열 모델
LSTM(Long Short Term Memory), GRU(Gated Recurrent Unit)
- GRU4Rec
- RRN: Recurrent Recommender Network
- WDN: Wide & Deep Network
- DeepFM
- DIN: Deep Interest Network
- DCN: Deep & Cross Network
- BST: Behavior Sequence Transformer
- TabNet
User-free 모델의 장점 (
$=\gamma_u$를 사용하지 않을 때의 장점)-
새로운 사용자에 대해 inference가 가능하다.
$\gamma_u$는 새로운 사용자가 발생할 때마다 재학습을 필요로 한다. -
이력이 거의 없는 사용자에 대한 대응이 가능하다.
MF 계열의 모델은 이런 상황에서
$\gamma_u$가 제대로 학습되지 않으므로 성능이 좋지 않다. -
CF 모델에서 종종 무시되곤 하는 sequential 시나리오에 대해 대응이 가능하다.
MF의
$\gamma_u$는 sequence를 고려하지 않는다.
- 실제 추천 시스템의 deployment를 고려하면, 새로운 사용자가 발생할 때마다 재학습이 필요한 점은 큰 단점이다.
- 따라서, user-free 모델은 전통적인 MF 계열의 모델보다 실용적이라고 볼 수 있다.
Latent Factor Model(Embedding)
-
ANN: Approximate Nearest Neighbor
- ANNOY: Approximate Nearest Neighbor Oh Yeah
- HNSW: Hierarchical Navigable Small World Graphs
- IVF: Inverted File Index
- PQ: Product Quantization — Compression
Clustering의 경우 다른 추천 방법론과 함께 사용하여 효과적인 추천 수행이 가능하다.
- 군집내의 다른 사용자가 선호하는 아이템 추천
- 군집화 이후 협력 필터링(Collaborative Filtering) 사용을 통해 예측 정확도 향상
- 비슷한 사용자 군집의 데이터를 추출하여 아이템 선호도를 계산하고, 이를 사전 확률(prior probability)로 활용하여 베이지안 방법론 적용
-
RL(강화 학습)
MAB: Multi-Armed Bandit
Hybrid CF
CARS: Context-aware Recommender System(맥락 기반 추천 시스템)
추천 라이브러리
- Surprise
- Implicit
- Lightfm
- MSrecommenders
- Spotlight
- Buffalo
- Torchrec
- TFrecommenders