모델에 데이터를 먹이는 방법
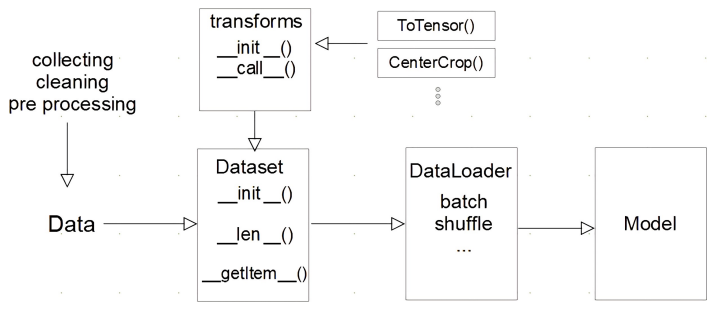
1. Dataset
모아놓은 데이터에 대해 Dataset이라는 클래스를 통해 시작, 길이, mapstyle 등을 선언해준다.
__getitems__() : 하나의 데이터를 불러올 때 어떤 식으로 데이터를 반환할 지를 선언해준다.
데이터 입력 형태를 정의하는 클래스
데이터를 입력하는 방식의 표준화
Image, Text, Audio 등에 따라 다르게 입력이 정의된다.
데이터의 형태에 따라 각 함수를 다르게 정의한다.
모든 것을 데이터 생성 시점에 처리할 필요는 없다.
image의 Tensor 변화는 학습에 필요한 시점에 변환해주면 된다.
데이터 셋에 대한 표준화된 처리 방법 제공이 필요하다.
후속 연구자 또는 동료들에게는 빛과 같은 존재가 될 수 있다.
최근에는 HuggingFace 등 표준화된 라이브러리를 사용한다.
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, text, labels): # 초기 데이터 생성 방법을 지정
self.labels = labels
self.data = text
def __len__(self):
return len(self.labels) # 데이터의 전체 길이
def __getitem__(self, idx): # idx 값을 입력으로 받고, dict 타입으로 데이터를 반환해준다.
label = self.labels[idx] # 반환되는 데이터의 형태 (X,y)
text = self.data[idx]
sample = {"Text": text,
"Class": label}
return sample
2. Transforms
Data Augumentation 등의 동작을 수행한다.
ToTensor() : 모아놓은 데이터를 Tensor로 변환해준다.
3. DataLoader
Data의 Batch를 생성해주는 클래스
정리된 데이터를 묶어서 모델에 넣어준다.
batch를 만들거나, shuffle 등의 역할을 수행한다.
학습 직전(GPU feed 전) 데이터의 변환을 책임진다.
Tensor로 변환 + Batch 처리가 메인 업무이다.
병렬적인 데이터 전처리 코드를 고민하게 된다.
DataLoader(dataset, batch_size=1, shuffle=False, **sampler=None**,
**batch_sampler=None**, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2, persistent_workers=False)
sampler : Data를 어떻게 뽑을 지 index를 정해주는 기법
collate_fn : [[data,label],[data,label]] 형태로 묶인 데이터를 [data,data],[label,label]로 바꿔준다.
흔하게 사용되지는 않는다.
- variable length(가변인자) 텍스트 처리에서 padding을 위해 많이 쓰인다.
- Sequence형 데이터를 처리할 때도 많이 쓰인다.
4. Model
예제
Datasets — Torchvision main documentation
Datasets & DataLoaders — PyTorch Tutorials 2.0.1+cu117 documentation
- DataLoader에서 사용할 수 있는 각 sampler들을 언제 사용하면 좋을지 논의해보기
- 데이터의 크기가 너무 커서 메모리에 한번에 올릴 수 없을 때 Dataset에서 어떻게 데이터를 불러오는 것이 좋을지 논의해보기