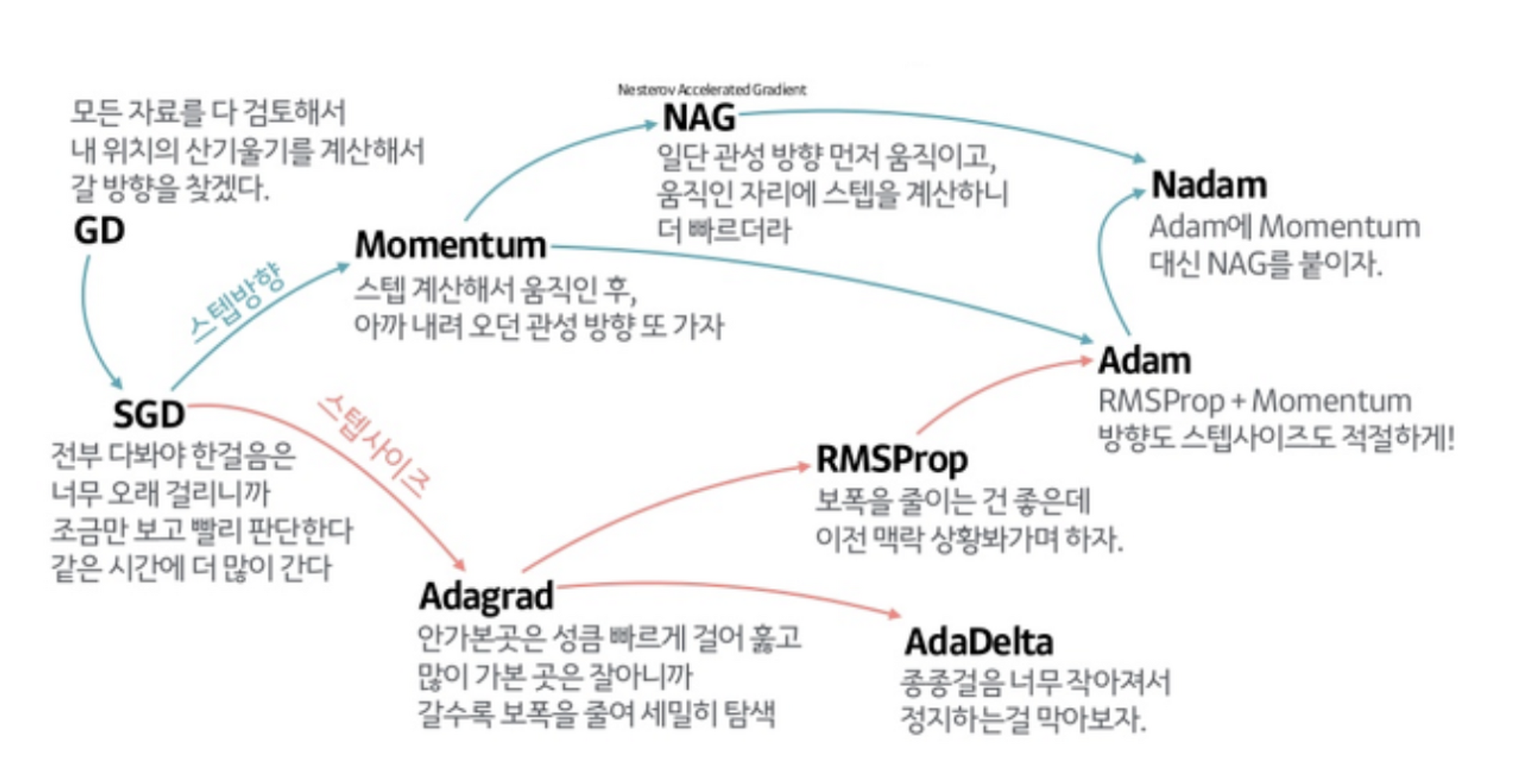
간단 요약
Loss의 미분값을 파라미터에 어떻게 반영할 지에 대한 방법
- 반영 방법 : loss의 미분 값을 파라미터에 어떻게 반영할 것인가?
- Learning rate : 한 번에 얼마나 반영할 것인가?
Background: Gradient Descent(GD)에서의 Issue
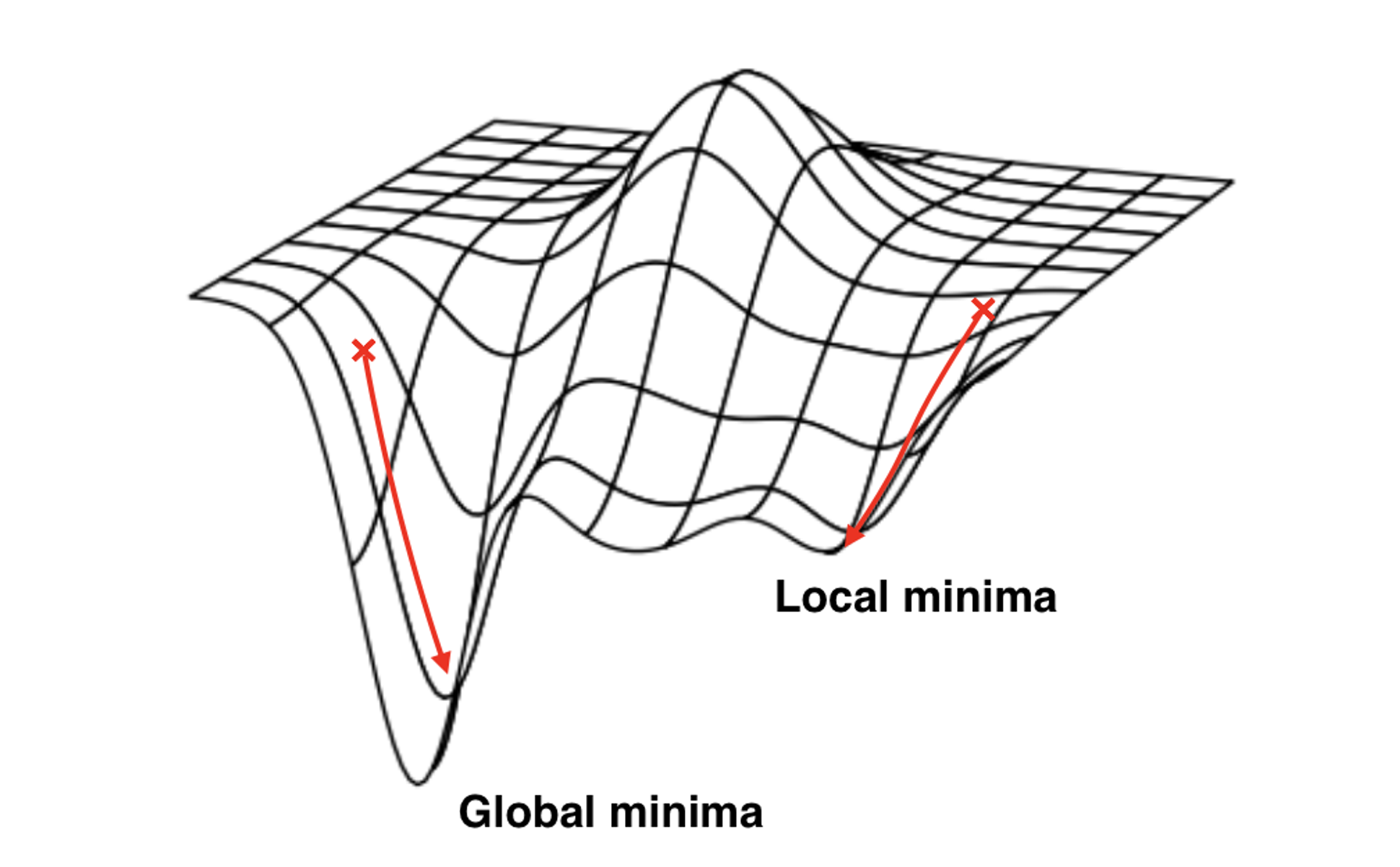
1. Local minima, Saddle point
 {: w=“700” h=“400” }
{: w=“700” h=“400” }
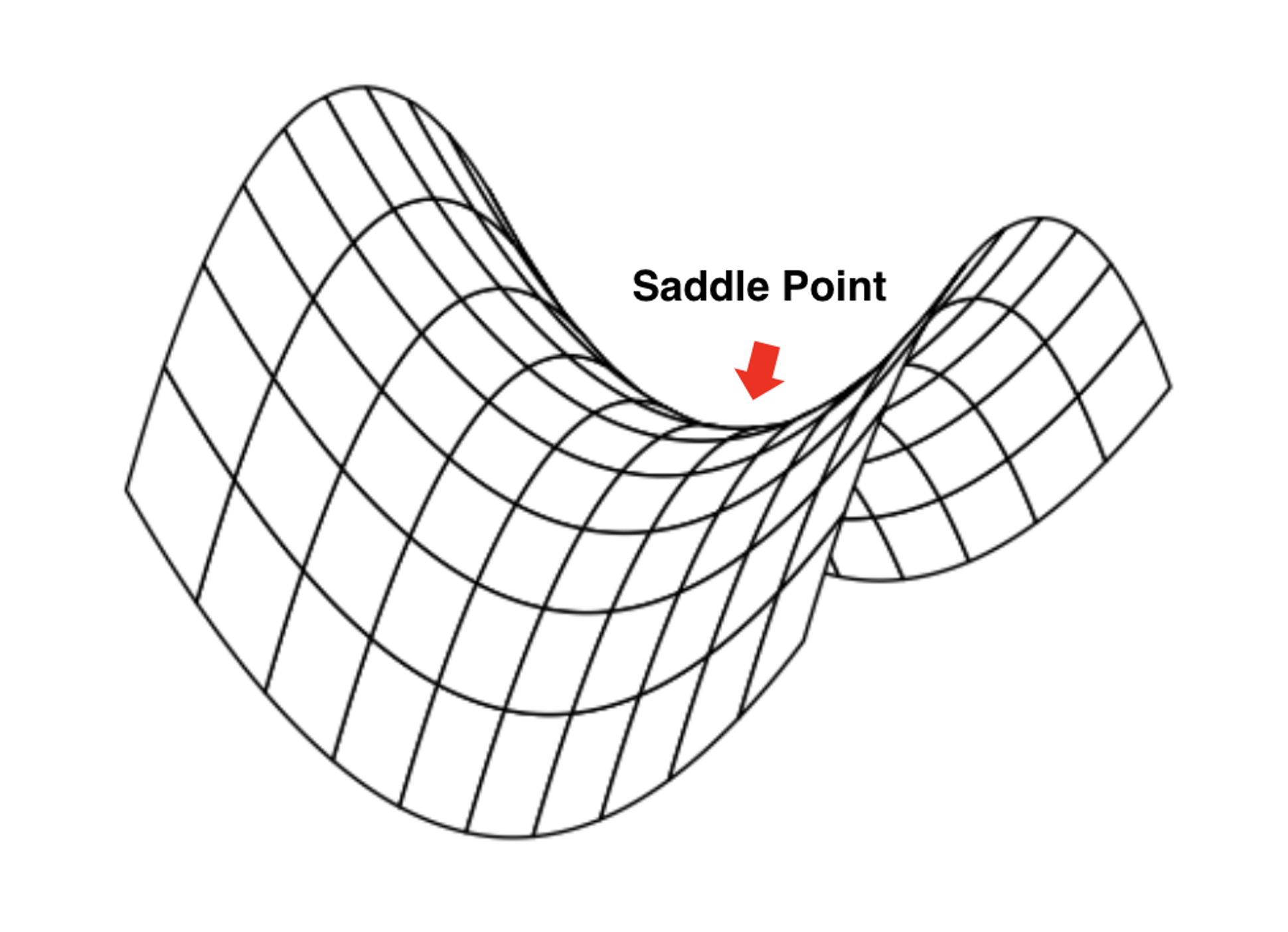
실제로는 Local Minima보단 안장점(saddle point)이 문제인 경우가 더 많다.
local minima가 되기 위해선 모든 변수 방향에서 loss가 증가해야 하는데, 이는 흔치 않다.
 {: w=“400” h=“250” }
{: w=“400” h=“250” }
 {: w=“400” h=“250” }
{: w=“400” h=“250” }
대신 위의 상황에서 gradient descent 알고리즘이 평평한 곳에 머물러버리는 문제가 발생할 수 있다.
꼭 머무르지 않더라도 주변이 평평하기 때문에 매우 더디게 학습이 진행되는 문제점도 있다.
2. 길 헤매기
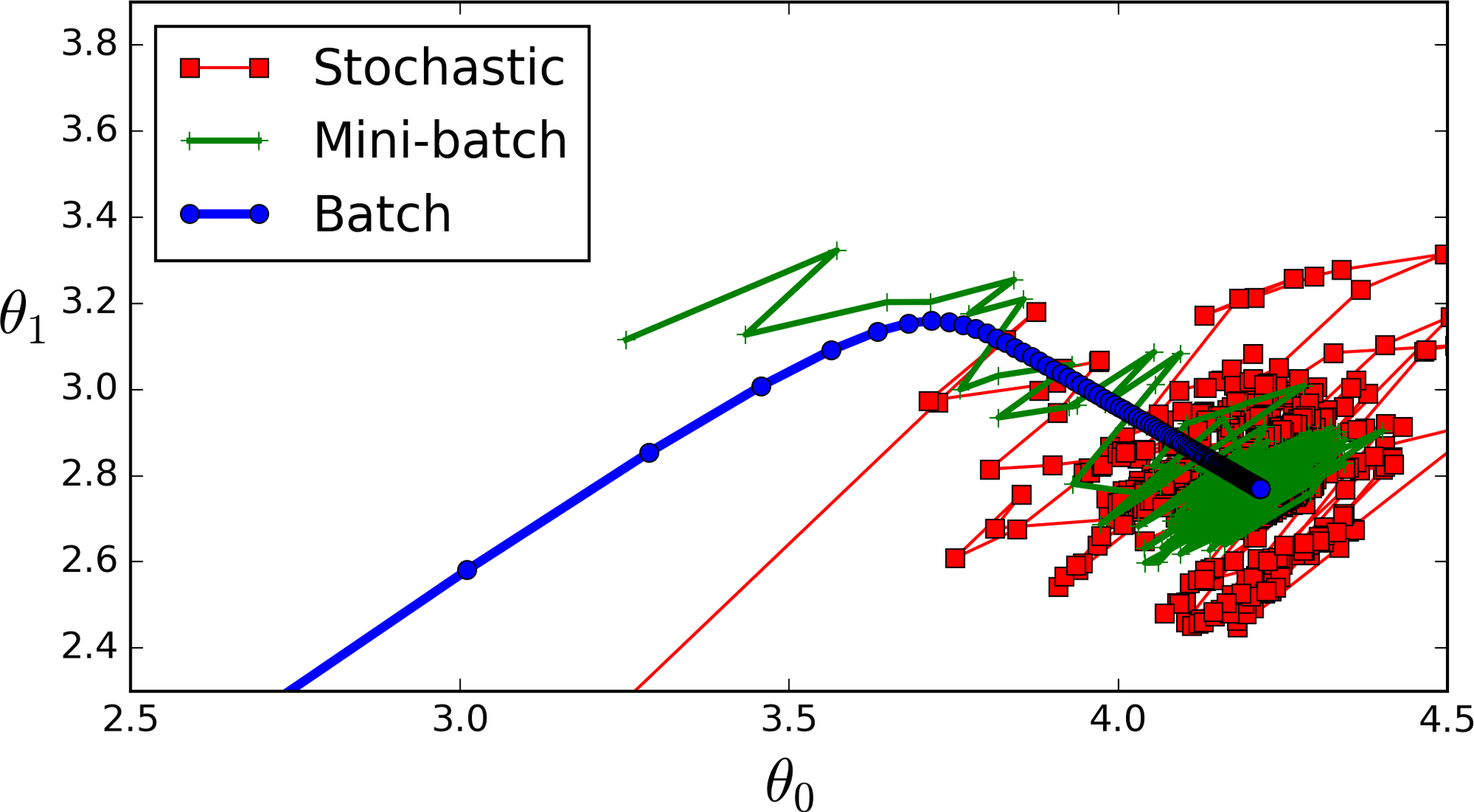 SGD, Mini-batch GD가 굉장히 헤매면서 길을 찾는다.
SGD, Mini-batch GD가 굉장히 헤매면서 길을 찾는다.
헤매는 정도를 줄일 필요가 있다.
이를 위해 Optimizer가 등장했다.
Optimizer에서는 SGD에서 크게 두 가지를 개선한다.
1. 방향
SGD에서 Optimum을 향해 나아갈 때, 위의 예시처럼 방향을 끊임없이 바꾸며 나아간다.
이보단, 올바른 방향으로 더 많이 가는 것을 원한다.
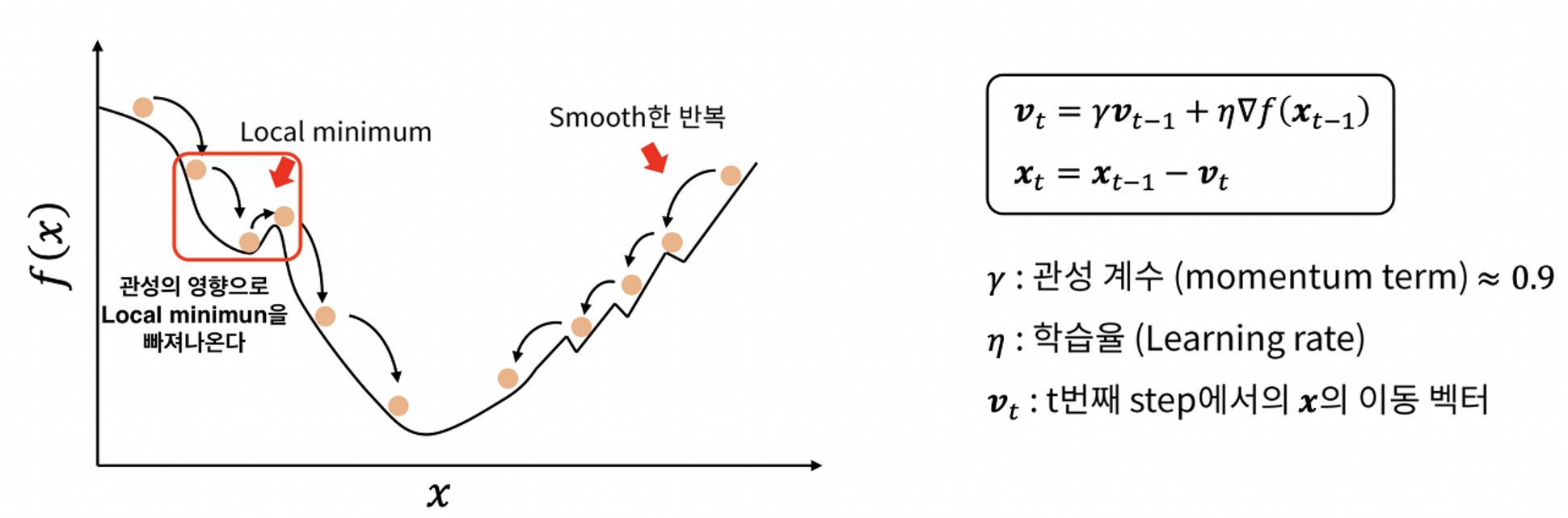
이를 위해 **관성(Momentum)**을 적용한다.
Momentum
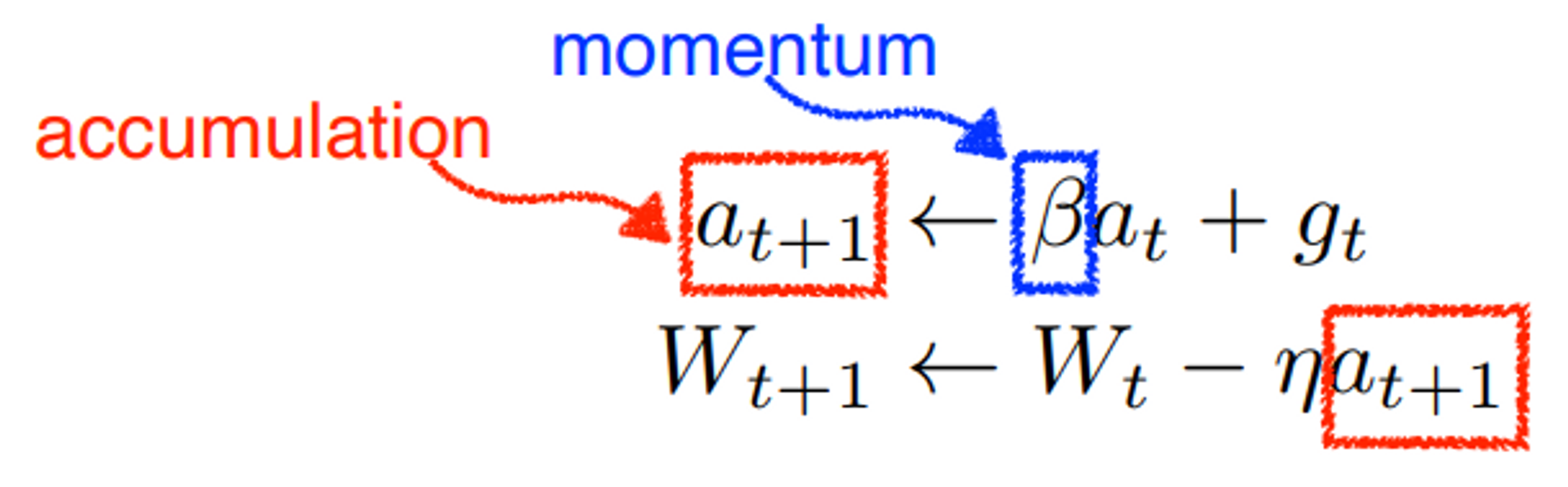
가중치를 갱신할 때, 이전에 나아갔던 방향도 반영을 해준다.
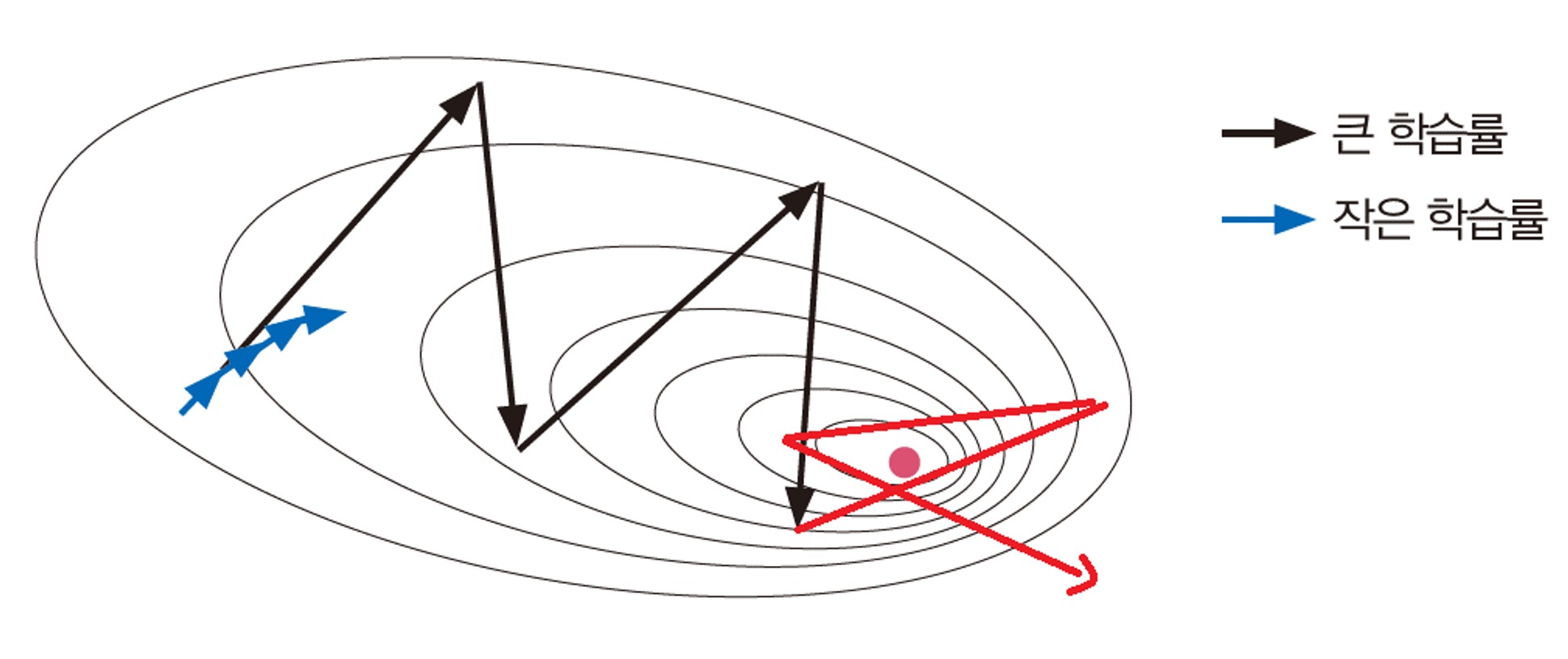
단점
학습률에 따라 minimum point에 수렴하지 못하는 경우가 발생한다.
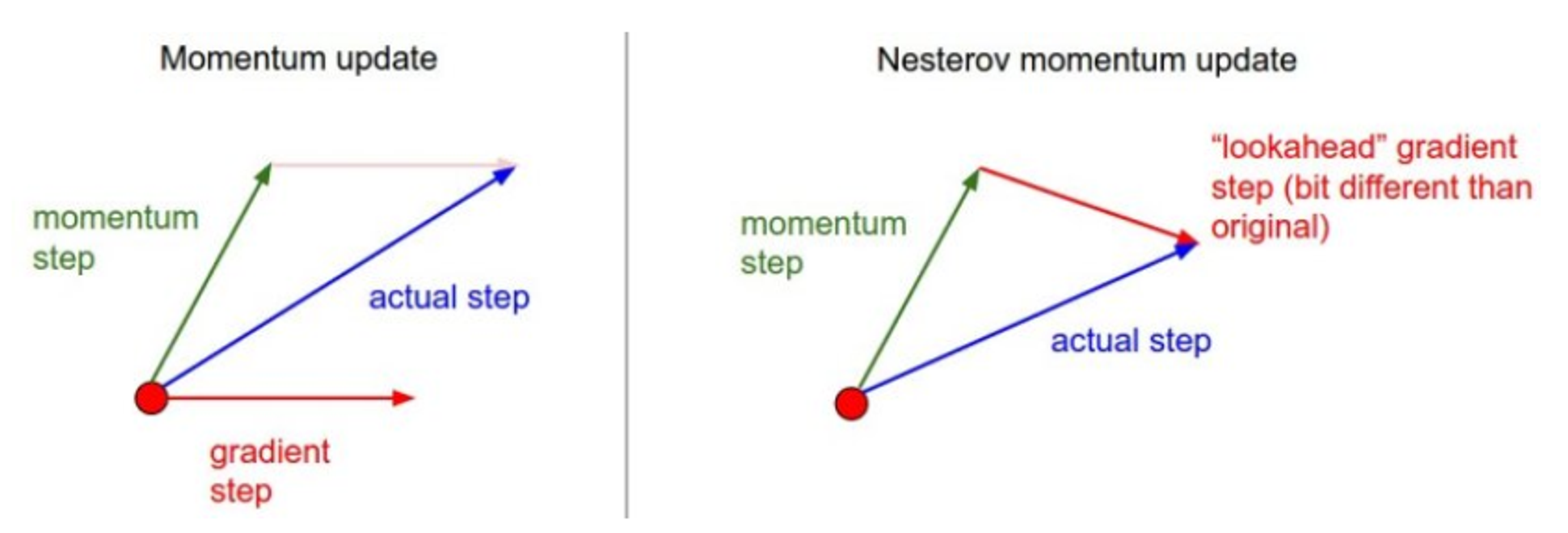
NAG : Nesterov Accelerated Gradient
Momentum의 단점을 개선한 방법.
관성 방향으로 먼저 이동한 후, gradient를 계산한다.
Momentum보다 수렴이 더 빠르다.
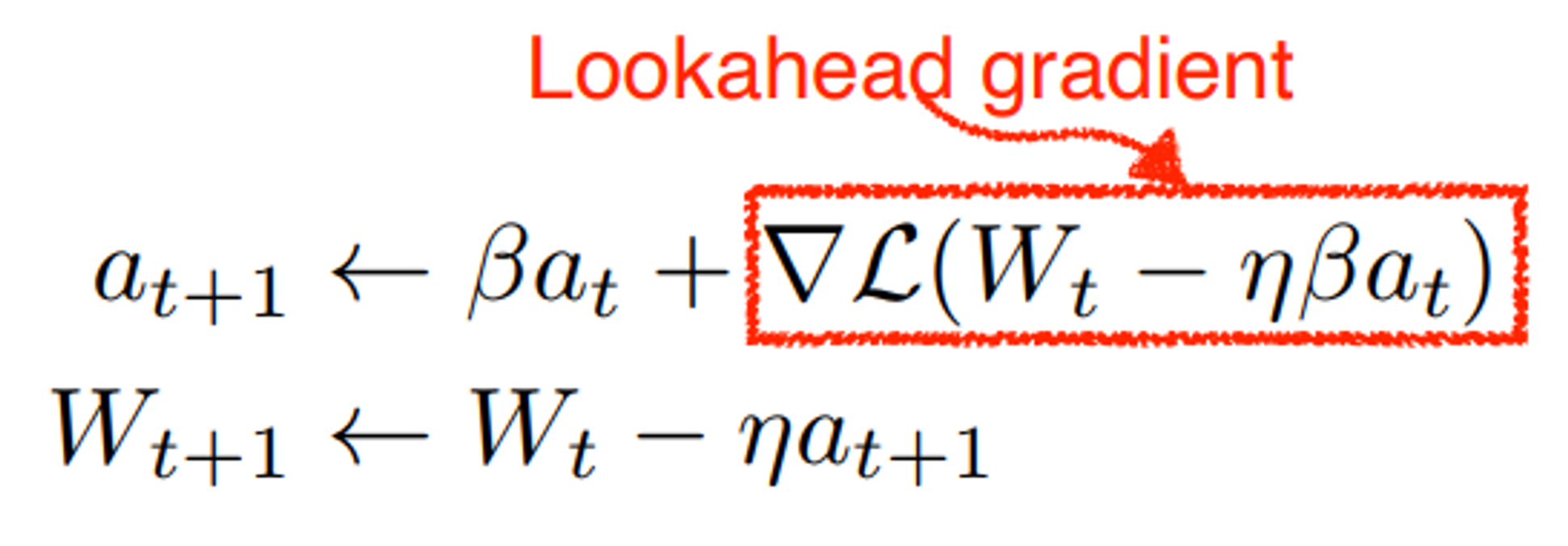
2. 거리(학습률)
Adagard
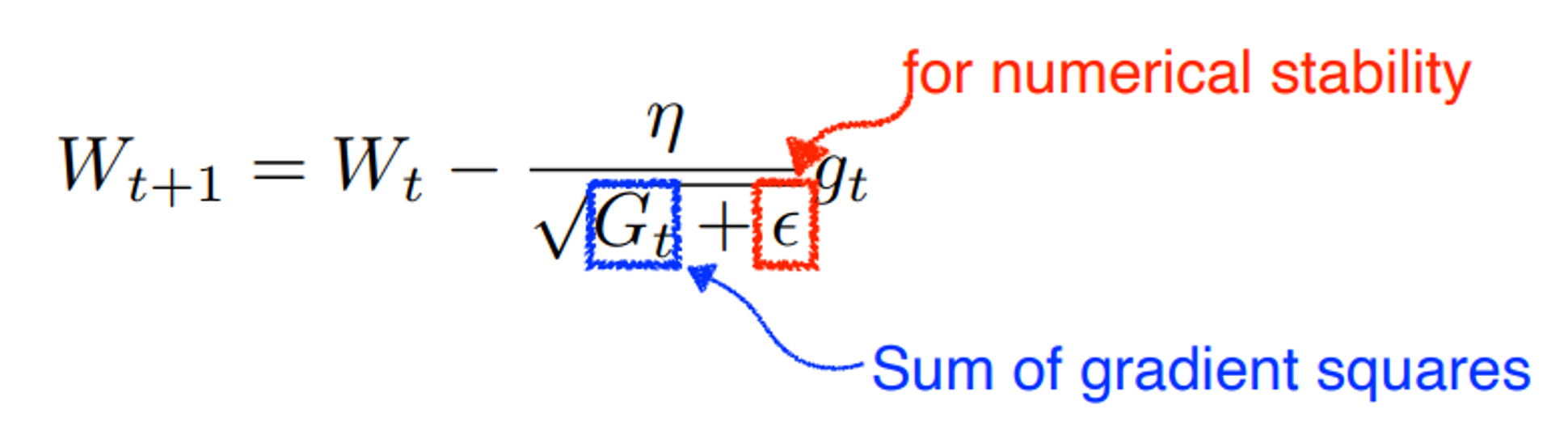
현재까지 값이 많이 변한 파라미터에 대해서는 적게 변화시키고, 적게 변한 파라미터는 많이 변화시킨다.
단점
$G_t$의 값은 계속 커지는데, 이 값이 무한대에 가깝게 커지게 되면 값이 0이 되어버린다.
즉, 이동을 멈춰버리게 된다.
Adadelta
Adagrad의 단점을 개선한 방법.
$G_t$가 너무 커지는 것을 방지한다.
Learning rate가 없어 변형이 불가능하기 때문에, 잘 쓰지 않는다.

RMSProp
Adadelta + stepsize.
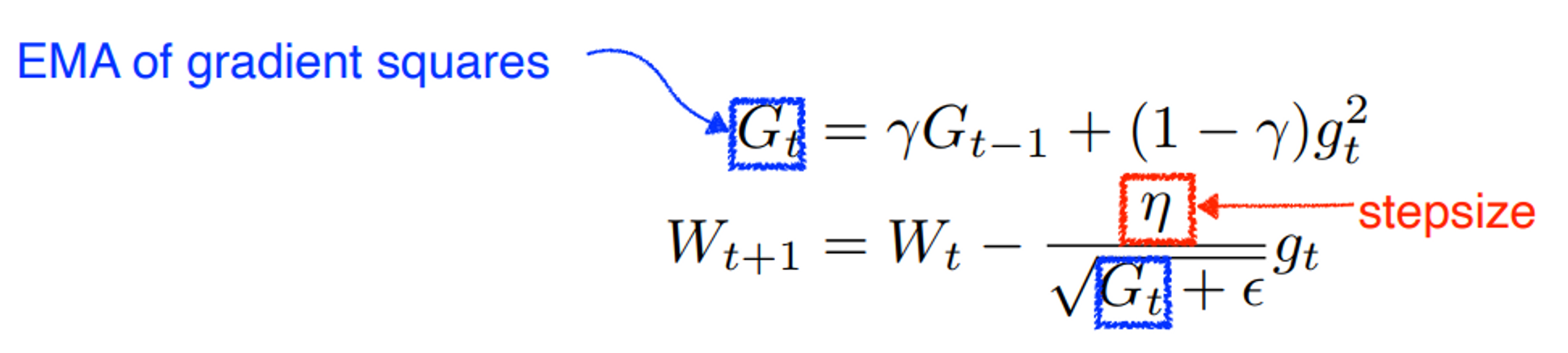
Adam
Momentum + RMSProp

가장 많이 쓰인다.