Neighborhood-based CF 혹은 Memory Based CF라고 부르기도 한다.
사용자 또는 아이템 간의 similarity 값을 계산하고 이를 rating prediction 또는 top-K ranking에 활용하는 방법
Similarity를 계산하기 위한 Metric으로 Jaccard, Cosine, Pearson 등을 활용한다.
장점
- 구현이 간단하고 이해하기 쉽다.
- Similarity를 활용하기 때문에 추천의 이유에 대한 직관적인 설명을 제공한다.
- 최적화나 훈련 과정이 필요 없다.
단점
-
Sparsity(희소성) 문제
NBCF를 적용하려면 적어도 sparsity ratio가 99.5%를 넘지 않는 것이 좋다.
데이터가 충분하지 않다면 유사도 계산이 부정확해진다. ⇒ 성능 저하
Cold Start
데이터가 부족하거나 혹은 아예 없는 유저, 아이템의 경우 추천이 불가능하다.
-
Scalability(확장성) 문제
-
유저와 아이템이 늘어날수록 유사도 계산이 늘어난다.
추론을 위한 많은 양의 Offline 계산이 요구된다.
-
유저, 아이템이 많아야 정확한 예측을 하지만 반대로 시간이 오래 걸린다.
-
-
이웃 데이터를 학습한다.
특정 주변 이웃에 의해 크게 영향을 받을 수 있다.
-
공통의 유저 / 아이템을 많이 공유해야만 유사도 값이 정확해진다.
-
유사도 값이 정확하지 않은 경우 이웃의 효과를 보기 어렵다.
UBCF: User-based CF(유저 기반 협업 필터링)
대상 유저와 유사도가 높은 유저들이 선호하는 아이템을 추천하는 방식
-
ex) 영화 평점
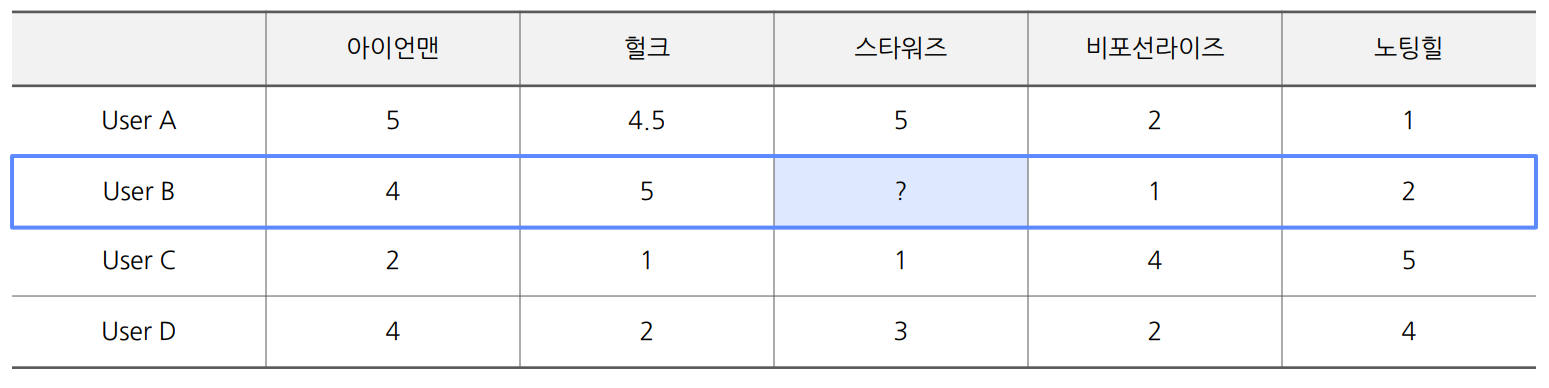
- User A가 User B와 선호도가 비슷하므로, User B의 스타워즈 평점은 높을 것이라고 예상한다.
평점 산출 방식
-
Absolute Rating
-
Average — 평균내기
모든 유저의 평점을 평균내서 평점을 예측한다.
-
Weighted Average — 유저의 유사도를 반영하여 평점 예측
유저 간의 유사도를 반영하여 평점을 예측한다.
한계
유저가 평점을 주는 기준이 제각기 다르다.
따라서, 각 유저별 발생하는 편차를 제대로 반영하지 못하게 된다.
-
-
Relative Rating
유저의 평점을 그대로 사용하지 않고, 유저의 평균 평점에서의 편차를 사용한다.
$$ \begin{gathered}\operatorname{dev}(u, i)=r(u, i)-\overline{r_u} \quad \text { for known rating } \\\widehat{\operatorname{dev}}(u, i)=\frac{\sum_{u \Omega^{\prime} \in \Omega_i} \operatorname{dev}\left(u^{\prime}, i\right)}{\left|\Omega_i\right|}=\frac{\sum_{u^{\prime} \in \Omega_i} r\left(u^{\prime}, i\right)-\overline{r_{u^{\prime}}}}{\left|\Omega_i\right|} \\\hat{r}(u, i)=\overline{r_u}+\frac{\sum_{u \prime \in \Omega_i} r\left(u^{\prime}, i\right)-\overline{r_{u^{\prime}}}}{\left|\Omega_i\right|}=\overline{r_u}+\widehat{\operatorname{dev}}(u, i)\end{gathered} $$-
ex) 유저 B의 스타워즈에 대한 예측 평점
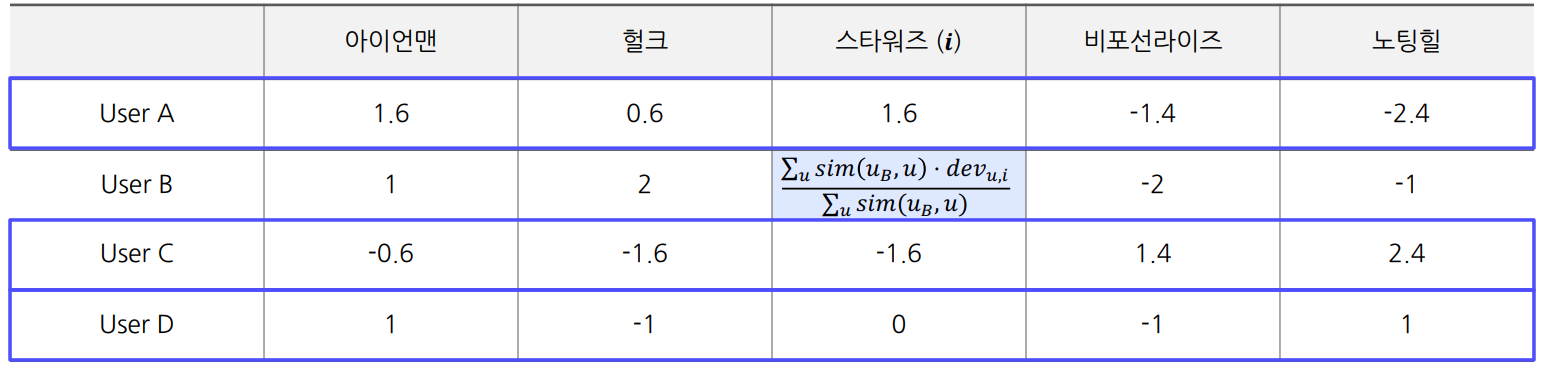
예측 Deviation = 0.23
$$ {1.6 \times 0.95 + (-1.6) \times (0.6) + 0 \times 0.85\over0.95 + 0.6 + 0.85} = 0.23 $$유저 B의 평점 평균 = 3
유저 B의 예측 평점 = 3.23
-
IBCF: Item-based CF(아이템 기반 협업 필터링)
타겟 아이템과 유사도가 높은 아이템 중 선호도가 큰 아이템을 추천하는 방식
장점
시간에 따라 유사도 변화가 적다.
User based CF에 비해 계산량이 적다.
-
ex) 영화 평점
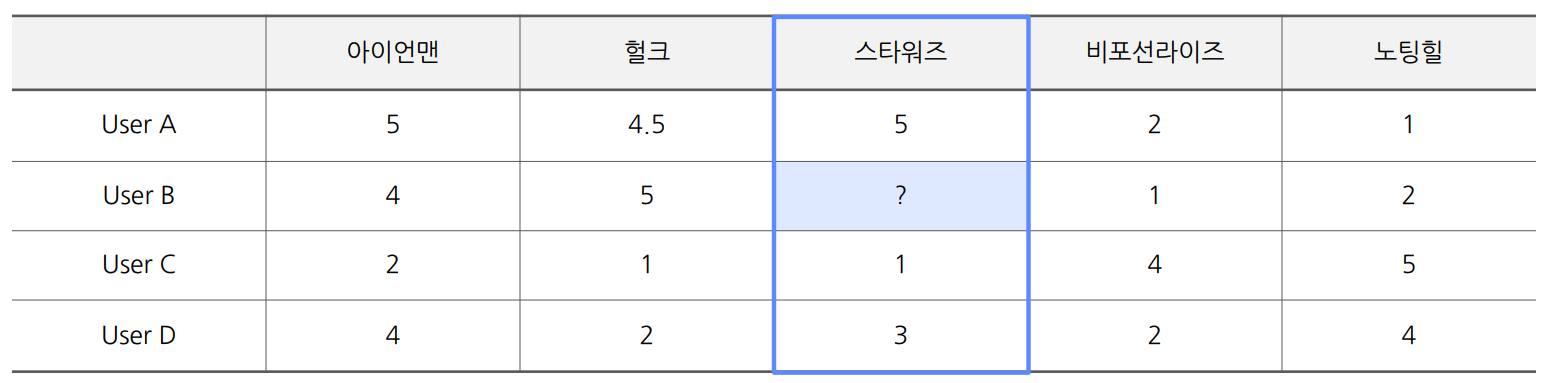
- 헐크와 스타워즈의 유저별 평점 분포가 비슷하므로, 유저 B의 스타워즈 평점이 높을 것이라 예측한다.
평점 산출 방식
-
Absolute Rating
-
Average — 평균내기
모든 아이템의 평점을 평균내서 평점을 예측한다.
-
Weighted Average — 아이템의 유사도를 반영하여 평점 예측
아이템 간의 유사도를 반영하여 평점을 예측한다.
이 때, 일부 아이템만 활용하여 평점을 예측하기도 한다.
-
-
Relative Rating
아이템의 평점을 그대로 사용하지 않고, 아이템의 평균 평점에서의 편차를 이용한다.
-
ex) 유저 B의 스타워즈에 대한 예측 평점
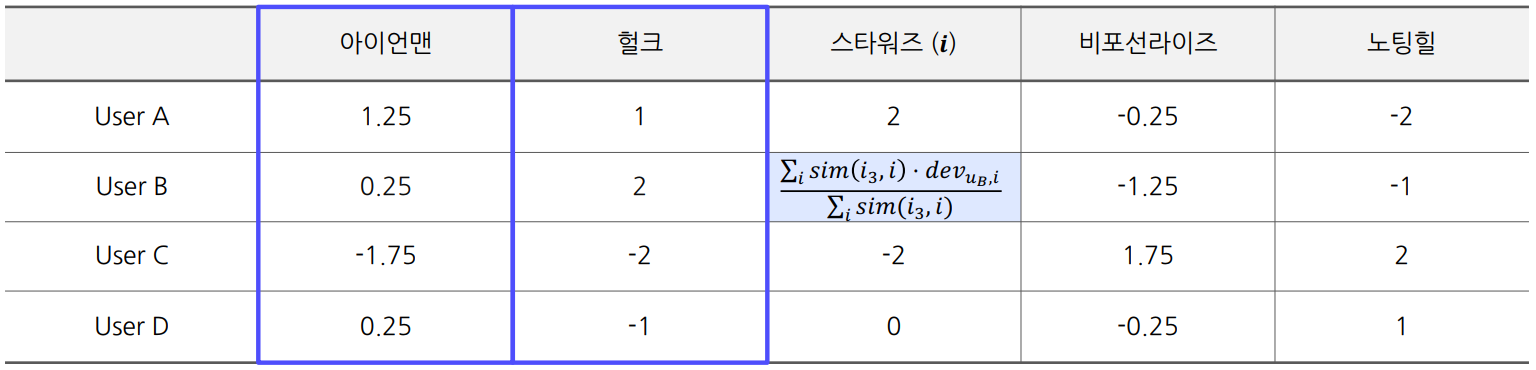 코사인 유사도 사용. 2-NN 기준 아이언맨 0.9, 헐크 0.95, 스타워즈 평균 3.0
코사인 유사도 사용. 2-NN 기준 아이언맨 0.9, 헐크 0.95, 스타워즈 평균 3.0예측 Deviation = 1.15
$$ {0.9 \times 0.25 + 0.95 \times2\over0.9 + 0.95} = 1.15 $$아이템 B의 평점 평균 = 3
유저 B의 예측 평점 = 4.15
-
Top-N Recommendation
대상 유저에 대한 아이템 예측 평점 계산이 완료되면, 평점순으로 정렬하여 상위 N개만 추천하기