Multiple Imputation Chained Equation(다중 산입 연립 방정식)
MICE 접근 방식에는 MI에서 언급된 동일한 개념이 적용된다.
- 값들은 각 방식에 따라 산입된 후
- 완전한 데이터셋에 대한 분석이 진행되고
- 결과가 합쳐진다.
다만 차이점으로, MI에서는 모든 변수에 대해 동시에 산입되지만, MICE에서는 각 변수의 값이 순차적으로 산입된다.
Process
-
누락된 데이터의 양이 가장 적은 변수가 가장 먼저 산입된다.
가장 첫 변수는 mean replacement(평균 대체) 방법으로 채워진다.
-
이후, 채워진 변수는 다른 변수를 채울 때 함께 예측 변수로 사용된다.
-
회귀로 결측값이 모두 채워진 그럴싸한 분포의 매개변수는 결측값을 재추정하는 데 사용된다.
-
이후 여러 사이클 동안 연립 방정식을 반복한다.
-
사이클이 완료되면 데이터가 “완전한” 데이터셋으로 저장된다.
각 변수는 개별적으로 산입되기 때문에, 각 변수 유형에 적합한 모델들이 사용된다.
- Binary Variable → Logistic regression Model
- Categorical Variable → Multinomial Logit Model
- Ordered categorical Variable → Ordered Logit Model
R 패키지에 MICE가 포함되어 있다.
MICE algorithm에는 FCS(Fully Conditional Specification)을 구현했다.
MICE에 내장된 Imputation 방법
- Pmm (any): Predictive mean matching
- Sample (any): Random sample from observed values
- Mean (numeric): Unconditional mean imputation
- norm.nob (numeric): Linear regression ignoring model error
- Logreg (binary): Logistic regression
- Polr (ordered): Proportional odds model
- Polyreg (unordered): Polytomous logistic regression
methods(mice)를 사용하면 imputation 할 수 있는 방법론을 쭉 알려준다.
하지만, 가독성이 좋지 않기 때문에 추천하진 않는다.
이보단 그냥 ?mice로 검색하여 확인하면 더 자세하게 잘 적혀있다.
md.pattern()
행렬이나 데이터프레임의 형태로 결측데이터의 유형들을 표로 나타낸다.
md.pattern(x, plot = TRUE, rotate.names = FALSE)
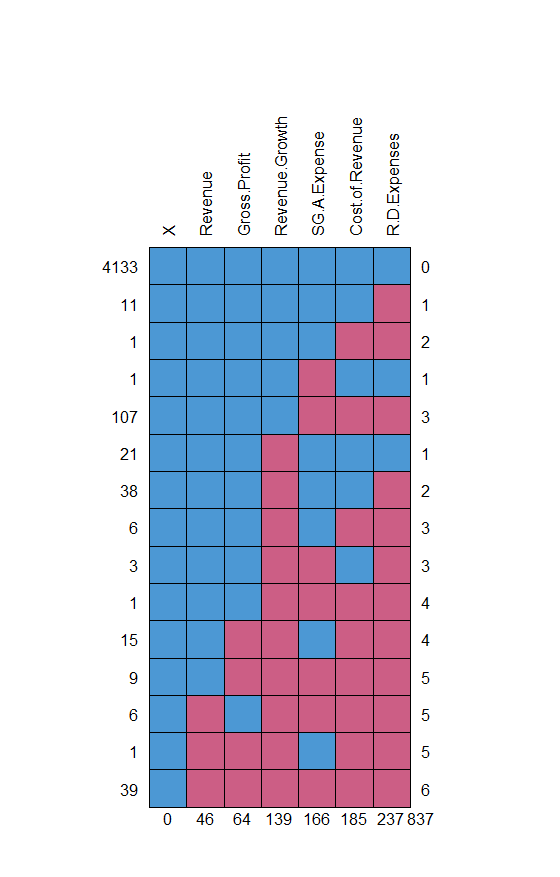
표 보는 방법
가장 왼쪽 열의 숫자: 해당 pattern으로 구성된 데이터의 개수
첫 번째 행을 보면, 결측치가 없는 데이터가 4133개라는 것을 알 수 있다.
두 번째 행을 보면, R.DExpemses만 결측치가 발생한 데이터가 11개라는 것을 알 수 있다.
가장 오른쪽 열의 숫자: 결측치가 발생한 변수(column)의 개수
최하단의 숫자: 각 변수에서 결측값의 총 개수
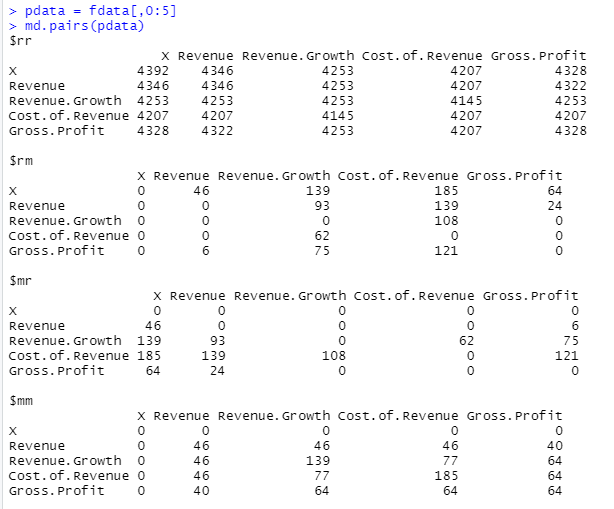
md.pairs()
출력 값에는 rr, rm, mr, mm 네 가지 구성 요소가 존재한다.
m은 Missing됨을 의미하고, r은 response, 존재함을 의미한다.