RNN의 장기문맥 의존성을 해결하기 위해 탄생한 모델
-
선별적 게이트라는 개념으로 선별 기억 능력을 확보한다.
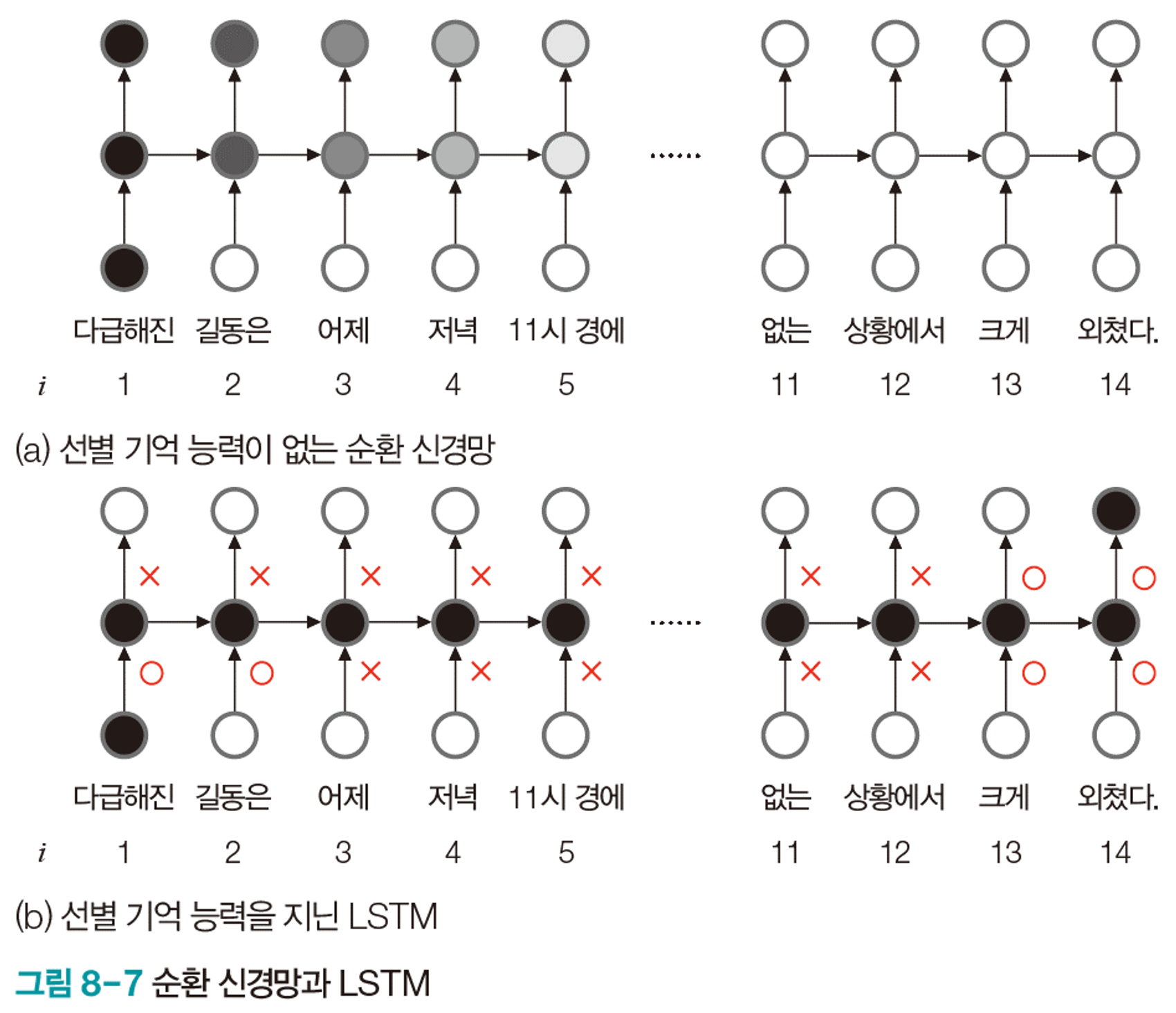
그림은 이해를 돕기위해 O,X로 표현했지만, 실제로는 게이트는 0~1 사이의 실수값으로 열린 정도를 조절한다.
게이트의 여닫는 정도는 가중치로 표현되며 가중치는 학습으로 알아낸다.
가중치
순환 신경망의 $\{U, V, W\}$에 4개를 추가하여 $\{U, U_i , U_o , W, W_i , W_o , V\}$
-
$i$: 입력 게이트 -
$o$: 출력 게이트 -
다양한 구조 설계가 가능하다.
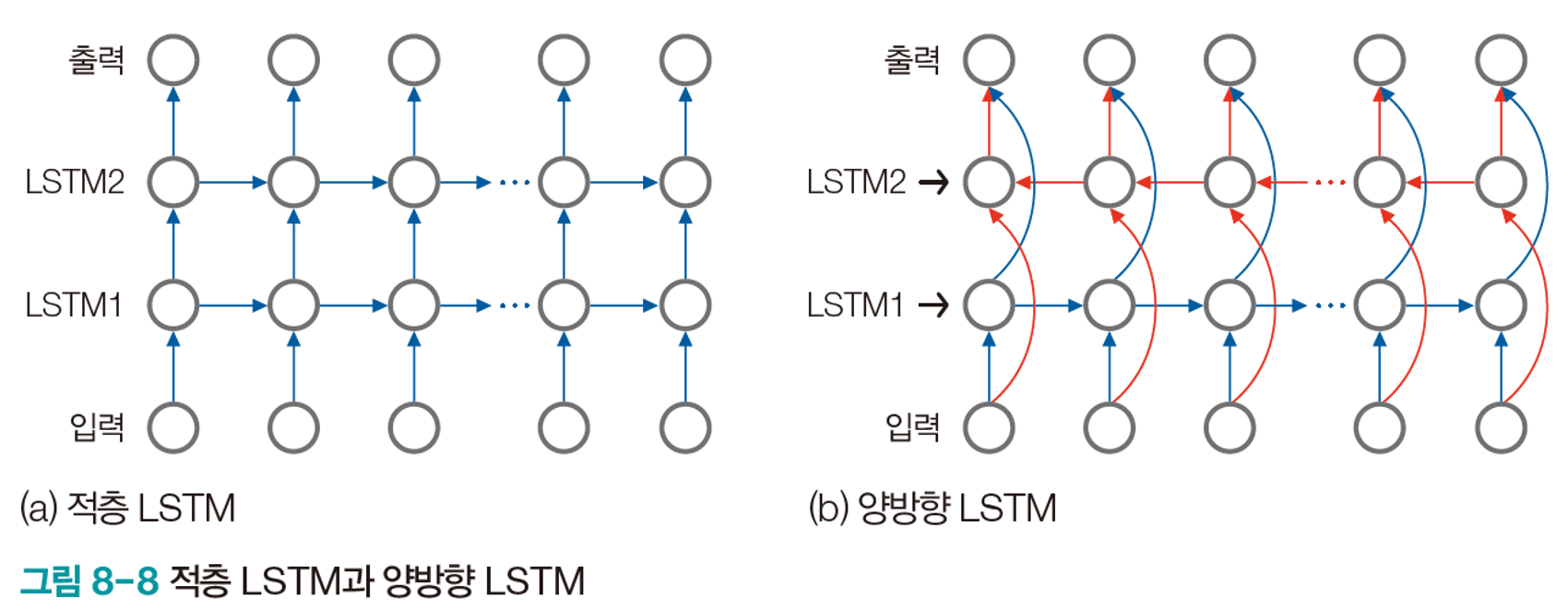
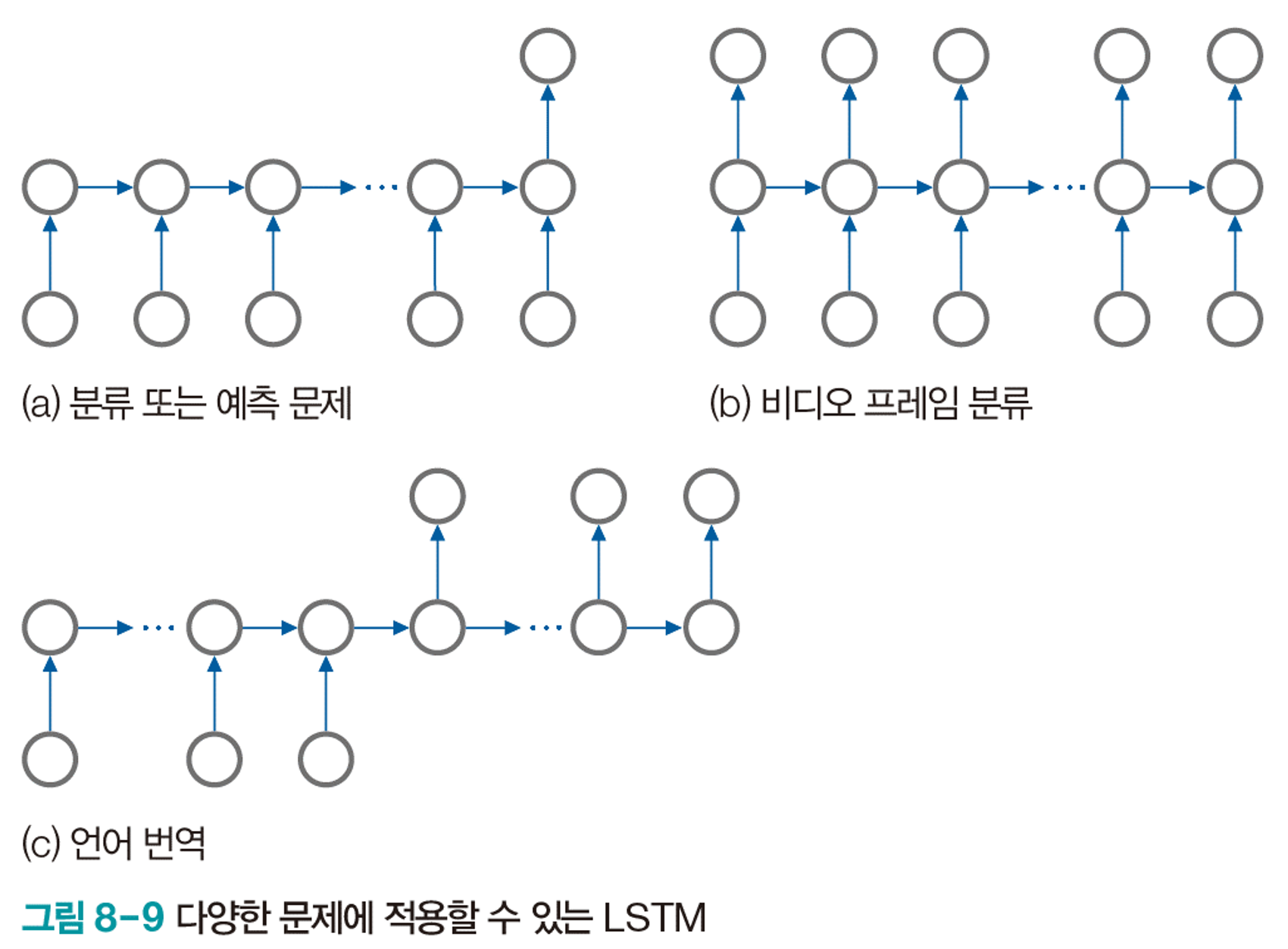
Model Concept
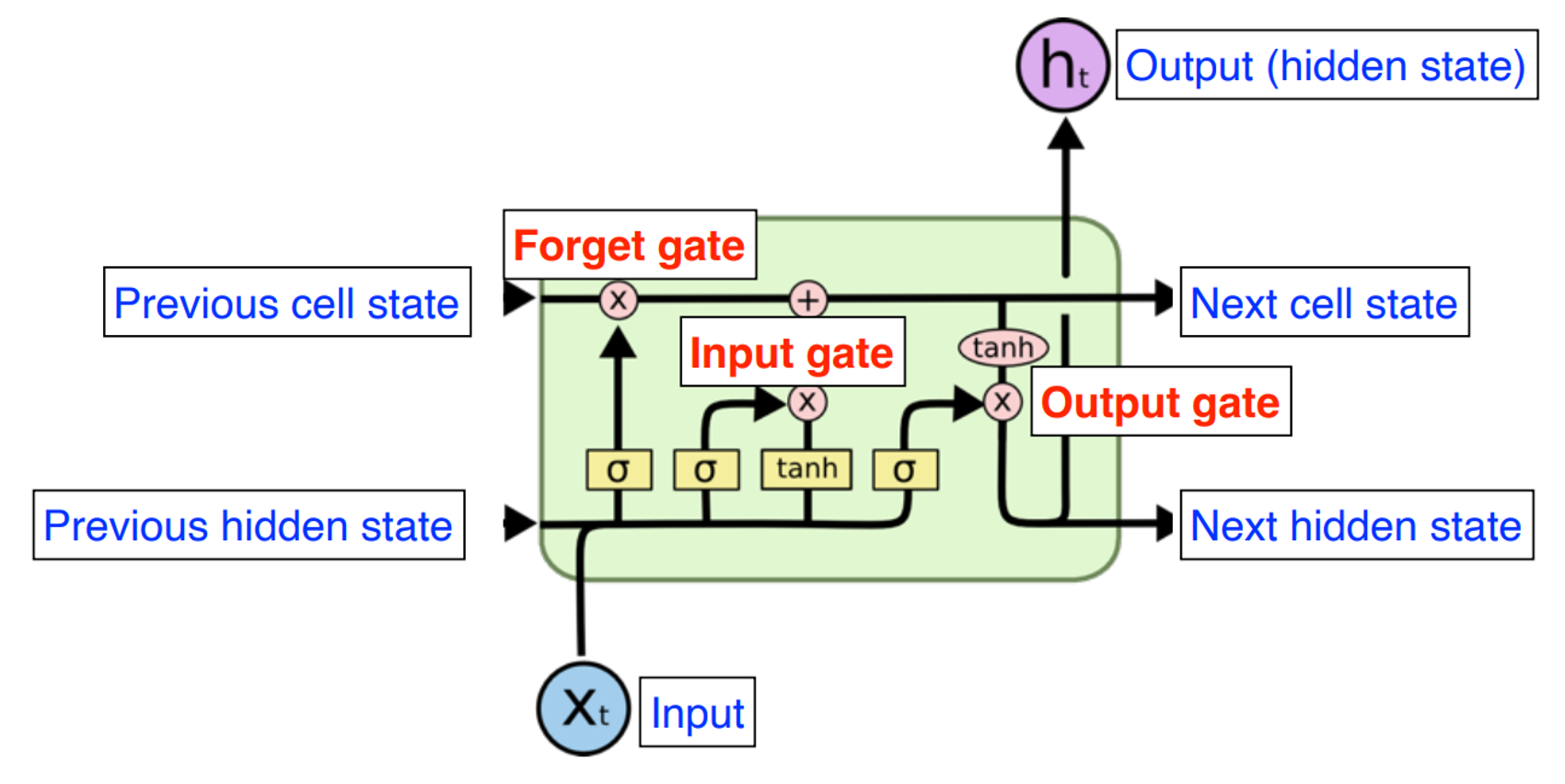
Cell State
-
LSTM의 핵심
-
모듈 그림에서 수평으로 그어진 윗 선에 해당
-
일종의 컨베이어 벨트
작은 linear interaction만을 적용시키면서 데이터의 흐름은 그대로 유지한다.
아무런 동작을 추가하지 않는다면, 정보는 전혀 바뀌지 않고 그대로 흐른다.
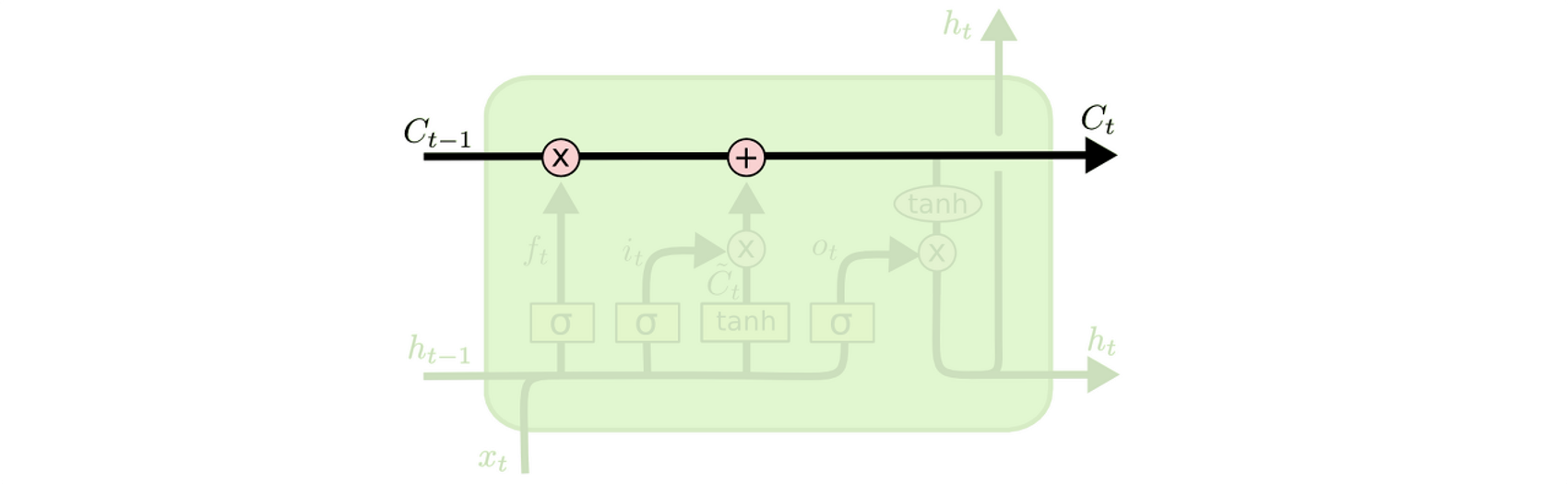
Cell State에서 gate에 의해 정보가 추가되거나 삭제된다.
Gate
-
Forget Gate
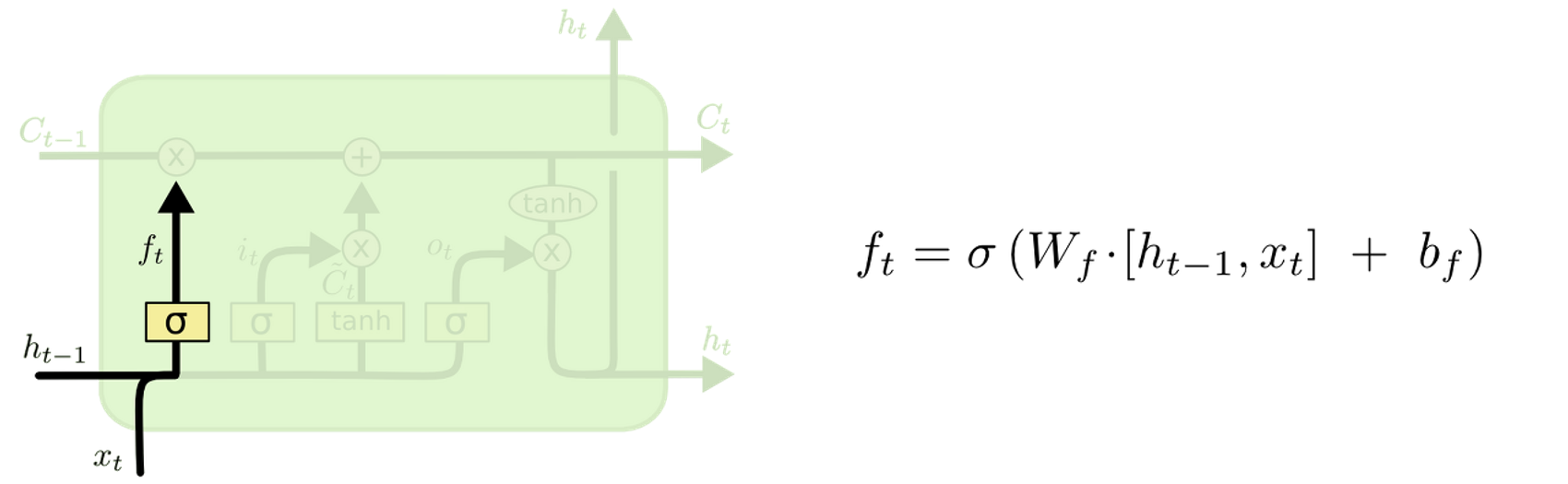
-
Input Gate
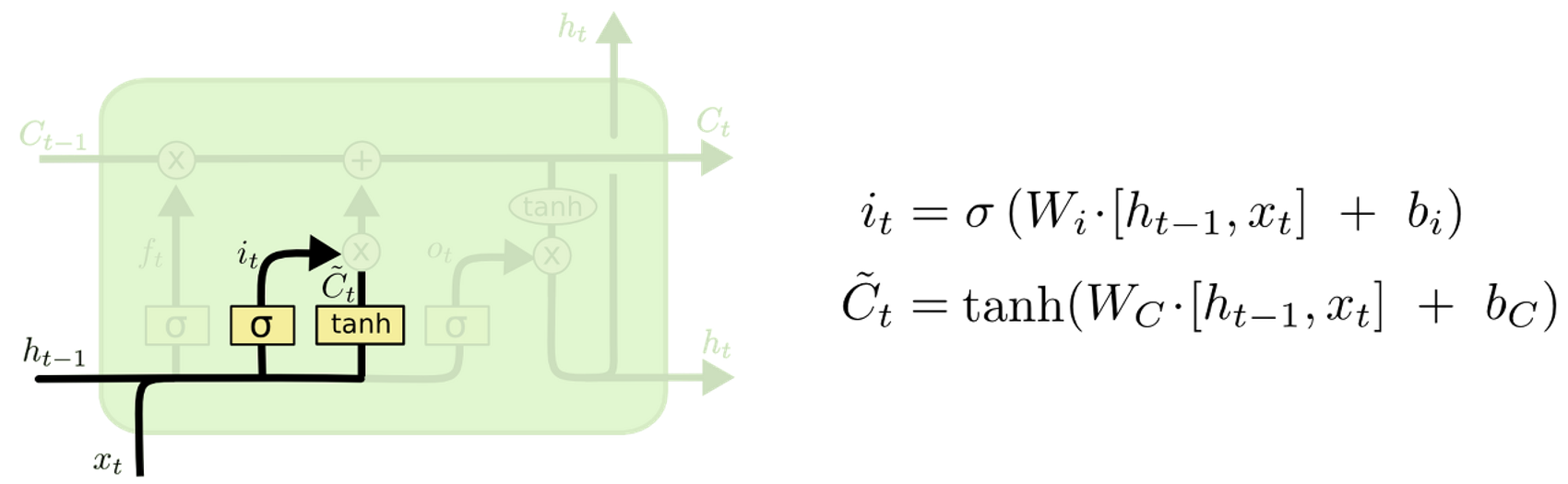
-
Cell State 업데이트
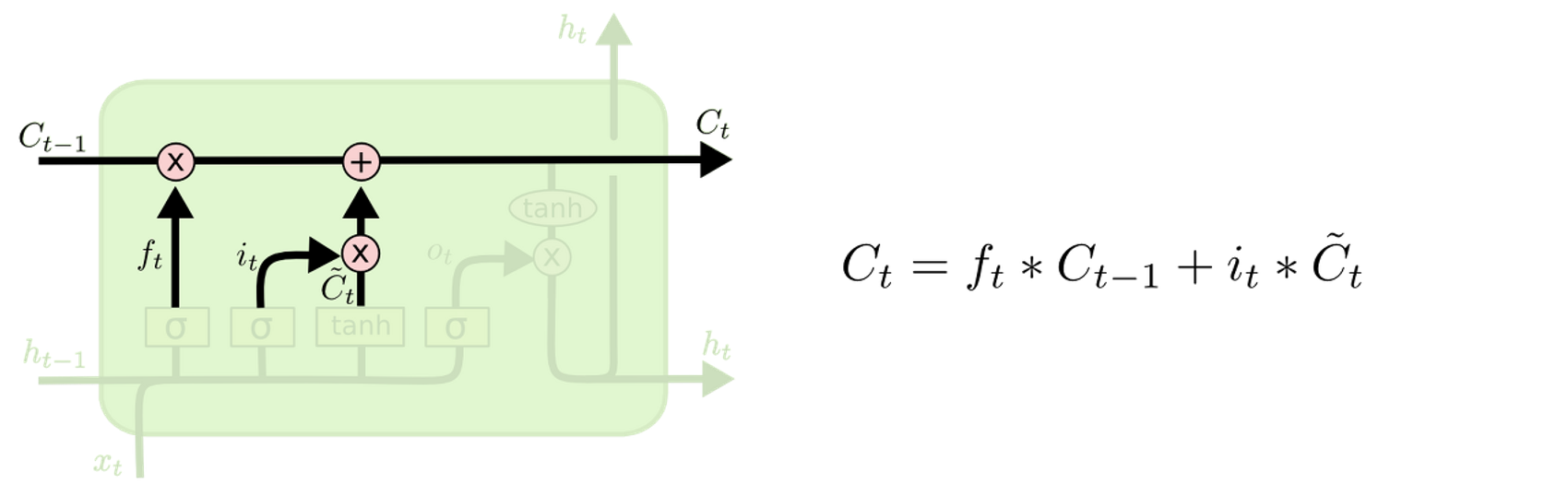
-
Output Gate
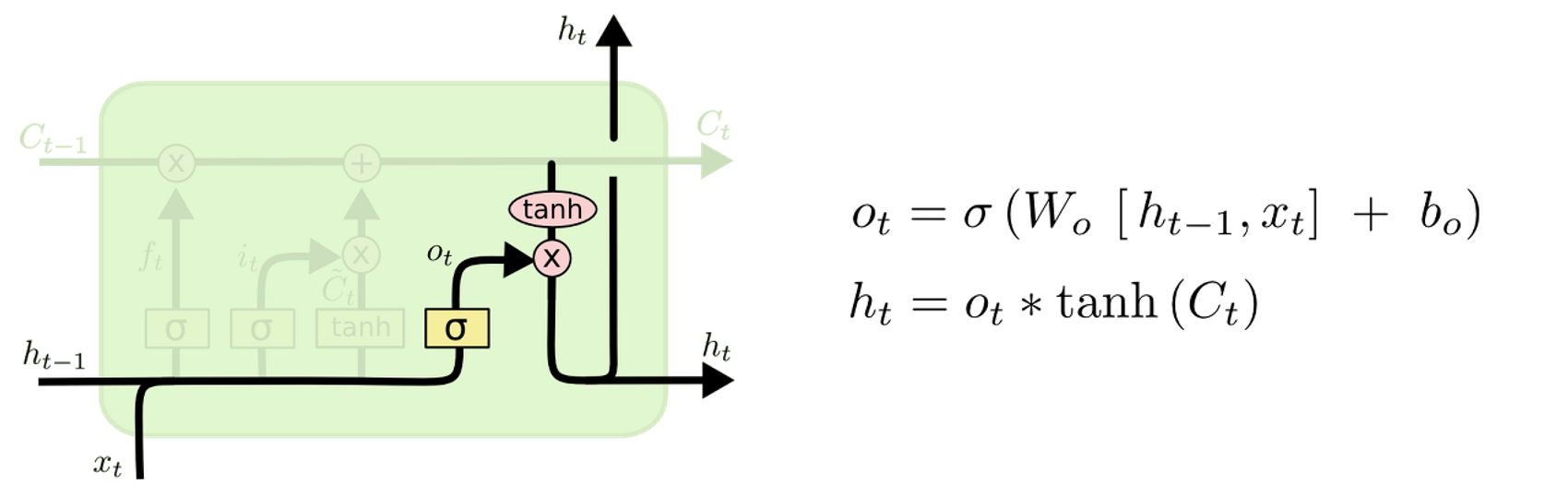
수식 요약
$$
\begin{aligned}f_t & =\sigma_g\left(W_f x_t+U_f h_{t-1}+b_f\right) \\i_t & =\sigma_g\left(W_i x_t+U_i h_{t-1}+b_i\right) \\o_t & =\sigma_g\left(W_o x_t+U_o h_{t-1}+b_o\right) \\\tilde{c}_t & =\sigma_c\left(W_c x_t+U_c h_{t-1}+b_c\right) \\c_t & =f_t \odot c_{t-1}+i_t \odot \tilde{c}_t \\h_t & =o_t \odot \sigma_h\left(c_t\right)\end{aligned}
$$
ft = sigmoid(np.dot(xt, Wf) + np.dot(ht_1, Uf) + bf) # forget gate
it = sigmoid(np.dot(xt, Wi) + np.dot(ht_1, Ui) + bi) # input gate
ot = sigmoid(np.dot(xt, Wo) + np.dot(ht_1, Uo) + bo) # output gate
Ct = ft * Ct_1 + it * np.tanh(np.dot(xt, Wc) + np.dot(ht_1, Uc) + bc)
ht = ot * np.tanh(Ct)
모델 요약
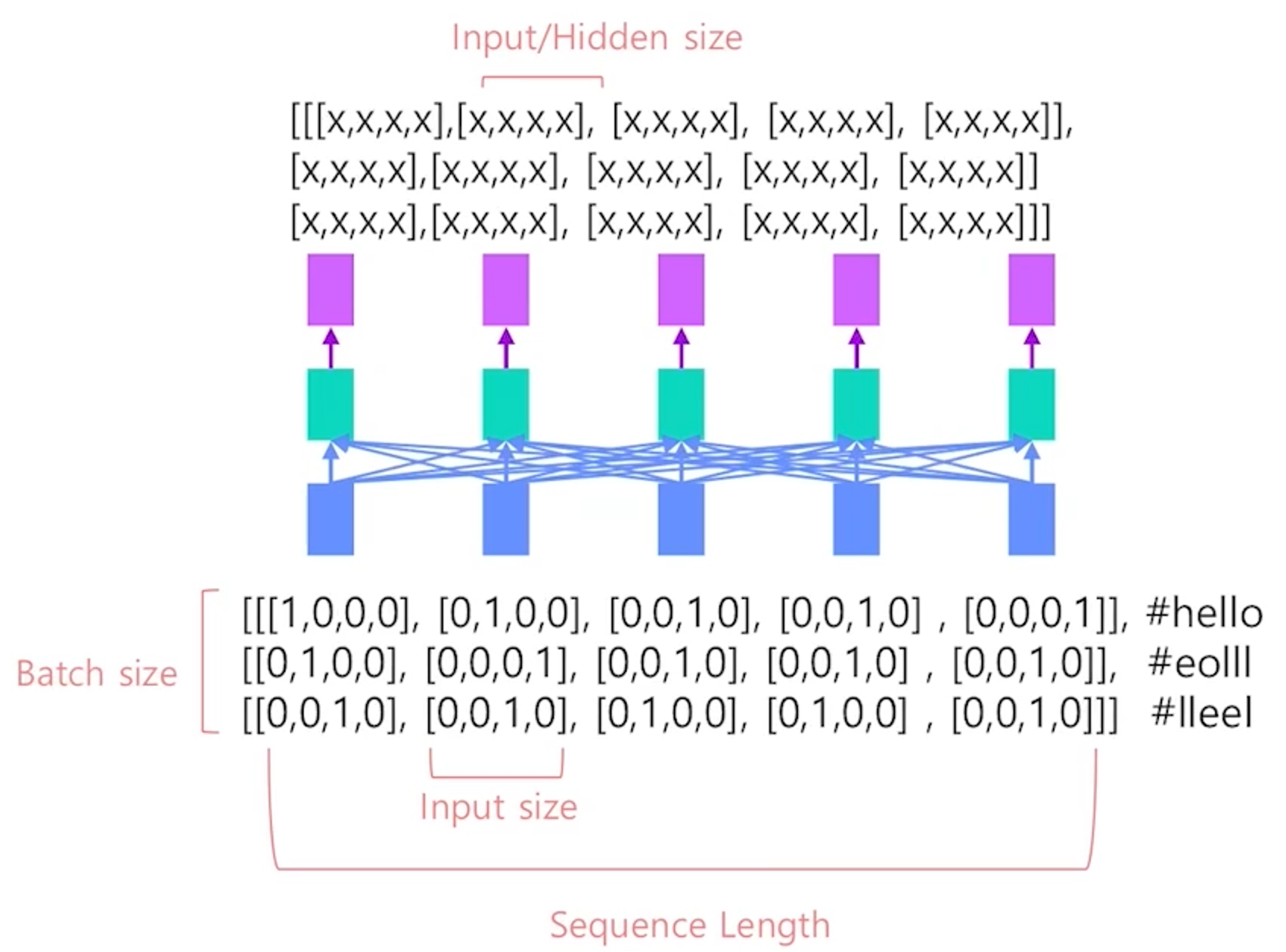
Input / Output Shape
import torch
import torch.nn as nn
# Size: [batch_size, seq_len, input_size/num_of_features]
input = torch.randn(3, 5, 4)
lstm = nn.LSTM(input_size=4, hidden_size=2, batch_first=True)
output, h = lstm(input)
output.size() # => torch.Size([3, 5, 2]), batch_size, seq_len, hidden_size
- LSTM을 활용하여 주식 가격을 예측 — 과거 5일의 종가를 예측하는 경우
- Seq_len = 5
- Input_size = 1(종가)
- Batch_size = N
- LSTM을 활용하여 주식 가격을 예측 — 과거 5일의 시가, 종가, 거래량을 예측하는 경우
- Seq_len = 5
- Input_size = 3(시가, 종가, 거래량)
- Batch_size = N
- LSTM을 활용하여 주식 가격을 예측 — 여러 연속형 변수와 범주형 변수가 포함된 경우
- Seq_len = 5
- Input_size = embedding size(시가, 종가, 거래량)
- Batch_size = N
Model
기본으로 제공되는 Feature들을 병합하여 LSTM에 주입한다.
def forward(self, input):
test, question, tag, _, mask, interaction, _ = input
batch_size = interaction.size(0)
#Embedding
embed_interaction = self.embedding_interaction(interaction)
embed_test = self.embedding_test(test)
embed_question = self.embedding_question(question)
embed_tag = self.embedding_tag(tag)
embed = torch.cat([embed_interaction,
embed_test,
embed_question,
embed_tag,], 2)
X = self.conb_proj(embed)
hidden = self.init_hidden(batch_size)
out, hidden = self.lstm(X, hidden)
out = out.contiguous().view(batch_size, -1, self.hidden_dim)
out = self.fc(out)
preds = self.activation(out).view(batch_size, -1)
return preds
LSTM + Attention
기존의 LSTM 모델에 Attention Layer을 추가한다.
def forward(self, input):
test, question, tag, _, mask, interaction, _ = input
batch_size = interaction.size(0)
#Embedding
embed_interaction = self.embedding_interaction(interaction)
embed_test = self.embedding_test(test)
embed_question = self.embedding_question(question)
embed_tag = self.embedding_tag(tag)
embed = torch.cat([embed_interaction,
embed_test,
embed_question,
embed_tag,], 2)
X = self.conb_proj(embed)
hidden = self.init_hidden(batch_size)
out, hidden = self.lstm(X, hidden)
out = out.contiguous().view(batch_size, -1, self.hidden_dim)
**extended_attention_mask = mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = extended_attention_mask.to(dtype=torch.float32)
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
head_mask = [None] * self.n_layers
encoded_layers = self.attn(out, extended_attention_mask, head_mask=head_mask)
sequence_output = encoded_layer[-1]**
out = self.fc(sequence_output)
preds = self.activation(out).view(batch_size, -1)
return preds
BERT
def forward(self, input):
test, question, tag, _, mask, interaction, _ = input
batch_size = interaction.size(0)
#Embedding
embed_interaction = self.embedding_interaction(interaction)
embed_test = self.embedding_test(test)
embed_question = self.embedding_question(question)
embed_tag = self.embedding_tag(tag)
embed = torch.cat([embed_interaction,
embed_test,
embed_question,
embed_tag,], 2)
X = self.conb_proj(embed)
**# Bert
encoded_layers = self.encoder(inputs_embeds=X, attention_mask=mask)
out=encoded_layers[0]**
out = out.contiguous().view(batch_size, -1, self.hidden_dim)
****
out = self.fc(sequence_output)
preds = self.activation(out).view(batch_size, -1)
return preds
참고 자료