✔️ 간단 요약
Sparsity와 Non-Informative를 효과적으로 해결한다.분별망에게 스파이를 심어 생성망이 분별망을 더 잘 속일 수 있도록 구성한다.
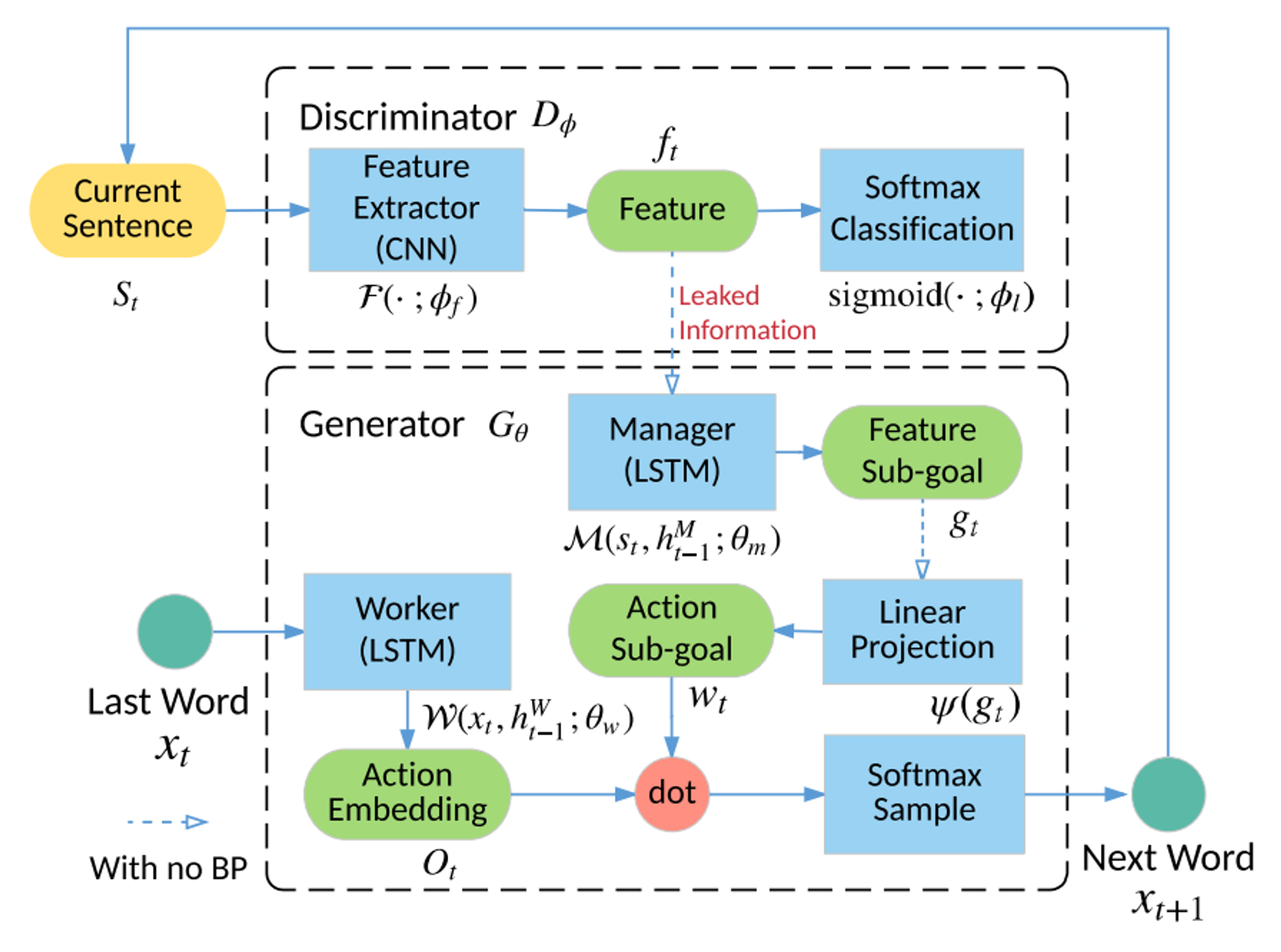
Hierarchical RL architecture (MANAGER, WORKER)
MANAGER (LSTM)
- 중재자 역할
- D로부터 고수준 feature representation을 받음 → Leakage
WORKER (LSTM)
$s_t$를 인코딩한 후, MANAGER가 넘겨준 Goal 임베딩과 결합한다. (내적)D가 넘겨준 guiding signal은 scalar 보상 값으로도 쓰이고, 문장 생성 과정에서 Goal 임베딩으로도 쓰인다.
logit, temperature parameter, highway network(gate), leakgan의 3가지 학습 방법, CNN for text classification, truncated normalization
배경
1. RNN – 문장 생성을 위한 가장 기본적인 방법
-
이전에 생성된 단어를 활용하여 다음 단어를 생성해내는 방식
-
ground-truth 단어들의 log-likelihood를 최대화한다. -
Supervising(Ground-Truth에 대한 설정) 필요
-
학습과 추론 단계의 불일치에 의해 편차가 발생
해결책으로 Scheduled sampling approach 제안 → 실패
2. GAN – 목적은 생성망 G의 성능을 개선하는 것
- 이를 위해 생성물의 진위 여부를 평가하는 분별망 D와 대립
- Jenson-Shannon 거리 활용
- 생성망의 성능이 충분히 좋아지면 분별망 갖다버림
3. GAN의 한계 및 해결책
-
제한적인 생성 가능한 문장의 길이(최대 20단어)
-
Non-informative guiding signal
문장 → 스칼라 값(guiding signal)
변환 과정에서 G가 학습하는 문장의 구조 및 의미를 보장하지 않음.
⇒ D가 G에게 점수와 함께 임베딩(feature representation)을 제공하여 해결
G는 D의 feature representation에 일치하도록 임베딩 학습
-
Sparsity
긴 문장 생성 시 binary guiding signal을 활용 → 전체 문장이 생성되었을 때만 가능
⇒ 문장 생성을 여러 단계(계층)으로 구분하여 signal을 더 많이 제공
Sparsity가 일부 해결될 뿐만 아니라, Task가 작아져 모델 학습 용이
but, 문장 생성 단계에 대한 사전 정의가 필요
⇒ 랜덤 문장 생성에는 적용 불가능
아이디어
Sparsity와 Non-Informative를 효과적으로 해결하기 위해 LeakGAN 제안한다.
분별망에게 스파이를 심어 생성망이 분별망을 더 잘 속일 수 있도록 구성한다.
MANAGER (LSTM)
- 중재자 역할
- D로부터 고수준 feature representation을 받는다. → Leakage
- 따라서 해당 정보는 전역적으로 관리된다.
- 물론 게임 진행 중에는 G에게 해당 정보를 제공하지 않는다.
- 해당 정보를 바탕으로 Goal 임베딩 생성 후 WORKER에게 넘긴다.
WORKER (LSTM)
- 현재까지 생성된 문장을 인코딩한 후, MANAGER가 넘겨준 Goal 임베딩과 결합한다. (내적)
D가 넘겨준 guiding signal은 scalar 보상 값으로도 쓰이고, 문장 생성 과정에서 Goal 임베딩으로도 쓰인다.
구체적 방법론
텍스트 생성 문제 → Sequential Decision Making Process
$s_t : t$시점까지 생성된 단어들.$(x_1,\dots, x_i, \dots, x_t)$$x_i:$단어(token)
생성망 $G_\theta$
$G_\theta:$ 파라미터가 $\theta$인 생성망
-
$s_t$를 전체 어휘 분포와 매핑시킨다.ex)
$x_{t+1}$에서$G_\theta( \cdot | s_t)$학습 -
분별망이 유출해준 정보를 계층 구조를 통해 효과적으로 포함하여 문장을 생성한다.
생성망의 계층 구조
D의 유출된 정보를 이용하기 위한 MANAGER-WORKER 계층 구조
-
MANAGER:
$t$시점마다 추출된$f_t$를 활용해$g_t$생성$f_t$를 LSTM에 입력한 후 goal vector$g_t$를 생성한다.$$ \begin{aligned} \hat{g}_t, h_t^M & = \mathcal{M}\left(f_t, h_{t-1}^M; \theta_m \right)\\ g_t & =\hat{g}_t /\left|\hat{g}_t\right| \end{aligned} $$-
$M:$LSTM 모델 -
$\mathcal{M}:$MANAGER 모듈 -
$\theta_m :$$\mathcal M$의 파라미터 -
$h_t:$t시점의 hidden state -
-
init, init_paramsdef __init__(self, batch_size, hidden_dim, goal_out_size): super(Manager, self).__init__() self.batch_size = batch_size self.hidden_dim = hidden_dim self.goal_out_size = goal_out_size self.recurrent_unit = nn.LSTMCell( self.goal_out_size, #input size self.hidden_dim #hidden size ) self.fc = nn.Linear( self.hidden_dim, #in_features self.goal_out_size #out_features ) self.goal_init = nn.Parameter(torch.zeros(self.batch_size, self.goal_out_size)) self._init_params() def _init_params(self): for param in self.parameters(): nn.init.normal_(param, std=0.1) self.goal_init.data = truncated_normal( self.goal_init.data.shape ) -
forwarddef forward(self, f_t, h_m_t, c_m_t): """ f_t = feature of CNN from discriminator leaked at time t, it is input into LSTM h_m_t = ouput of previous LSTMCell c_m_t = previous cell state """ h_m_tp1, c_m_tp1 = self.recurrent_unit(f_t, (h_m_t, c_m_t)) sub_goal = self.fc(h_m_tp1) # 하위 텐서의 p-norm이 값 maxnorm보다 낮도록 # 차원에 따라 입력의 각 하위 텐서가 정규화되는 텐서를 반환한다. sub_goal = torch.renorm(sub_goal, 2, 0, 1.0) return sub_goal, h_m_tp1, c_m_tp1
-
-
-
WORKER: MANAGER의
$g_t$를 토대로 보상을 높이는 다음 단어 생성MANAGER의
$g_t$를 포함하기 위해 가중치 행렬$W_\psi$로 최근 c개의 목표들에 대한 선형 변환을 수행한다.이를 통해 k차원의 goal embedding vector
$w_t$를 얻는다.$$ w_t=\psi\left(\sum_{i=1}^c g_{t-i}\right)=W_\psi\left(\sum_{i=1}^c g_{t-i}\right) $$$\psi:$선형 변환(행렬 곱셈)
$$ \begin{aligned}O_t, h_t^W & =\mathcal{W}\left(x_t, h_{t-1}^W ; \theta_w\right) \\ G_\theta\left(\cdot \mid s_t\right) & =\operatorname{softmax}\left(O_t \cdot w_t / \alpha\right) \end{aligned} $$-
$\mathcal W:$WORKER 모듈 -
$x_t:$input. (t 시점의 단어) -
$\theta_w :$$\mathcal W$의 파라미터 -
$O_t :$행렬 내적으로$w_t$와 추가로 결합된 행렬.$\|V\| \times k$모든 단어에 대한 벡터 집합을 의미한다.
따라서,
$O_t \cdot w_t$는 모든 단어에 대해 logit을 계산한다. -
$\alpha :$generation entropy를 조절하기 위한 temperature parameter즉, 생성되는 문장의 참신함을 조절한다.
softmax를 통해 현재까지 생성된 단어 집합
$s_t$에서 최종 action space 분포를 결정한다.-
-
init, init_paramsdef __init__(self, batch_size, vocab_size, embed_dim, hidden_dim, goal_out_size, goal_size): super(Worker, self).__init__() self.batch_size = batch_size self.vocab_size = vocab_size self.embed_dim = embed_dim self.hidden_dim = hidden_dim self.goal_out_size = goal_out_size self.goal_size = goal_size **self.emb = nn.Embedding(self.vocab_size, self.embed_dim)** **self.recurrent_unit = nn.LSTMCell(self.embed_dim, self.hidden_dim)** **self.fc = nn.Linear(self.hidden_dim, self.goal_size*self.vocab_size)** **self.goal_change = nn.Parameter(torch.zeros(self.goal_out_size, self.goal_size))** self._init_params() def _init_params(self): for param in self.parameters(): nn.init.normal_(param, std=0.1) -
forwarddef forward(self, x_t, h_w_t, c_w_t): """ x_t = last word h_w_t = last output of LSTM in Worker c_w_t = last cell state of LSTM in Worker """ x_t_emb = self.emb(x_t) h_w_tp1, c_w_tp1 = self.recurrent_unit(x_t_emb, (h_w_t, c_w_t)) output_tp1 = self.fc(h_w_tp1) output_tp1 = output_tp1.view(self.batch_size, self.vocab_size, self.goal_size) return output_tp1, h_w_tp1, c_w_tp1
-
생성망 G 학습
앞에서 설명한 G의 모든 과정은 미분 가능한 구조로 되어있다.
따라서, REINFORCE와 같은 policy gradient algorithm을 적용하여 모델을 학습할 수 있다.
LeakGAN 모델이 유의미한 의미 패턴을 찾을 수 있도록 MANAGER와 WORKER는 개별적으로 훈련한다.
-
MANAGER — 식별 가능한 feature space에서의 이동 방향을 예측하도록 훈련된다.
MANAGER의 gradient
$$ \nabla_{\theta_m}^{\mathrm{adv}} g_t=-Q_{\mathcal{F}}\left(s_t, g_t\right) \nabla_{\theta_m} d_{\cos }\left(f_{t+c}-f_t, g_t\left(\theta_m\right)\right) $$-
$Q_{\mathcal{F}}\left(s_t, g_t\right)=Q\left(\mathcal{F}\left(s_t\right), g_t\right)=Q\left(f_t, g_t\right)=\mathbb{E}\left[r_t\right]$몬테 카를로 탐색으로 추정한 현재 정책에 대한 보상 기댓값
-
$d_{\cos }:$cosine similarity(similarity인지 distance인지 확인해보기)$c$번의 전환 후 feature representation의 변화$(f_{t+c} - f_t)$와 목적 벡터$g_t$의 차이
손실 함수에서는 높은 보상을 달성하기 위해
$g_t$가 특징 공간의 전환과 일치하도록 강제한다.$$ \begin{aligned}& \nabla_{\theta_w} \mathbb{E}_{s_{t-1} \sim G}\left[\sum_{x_t} r_t^I \mathcal{W}\left(x_t \mid s_{t-1} ; \theta_w\right)\right]\\ = & \mathbb{E}_{s_{t-1} \sim G, x_t \sim \mathcal{W}\left(x_t \mid s_{t-1}\right)}\left[r_t^I \nabla_{\theta_w} \log \mathcal{W}\left(x_t \mid s_{t-1} ; \theta_w\right)\right]\end{aligned} $$ -
-
WORKER — MANAGER의 지시를 따르도록 보상이 주어진다.
REINFORCE 알고리즘을 활용하여 보상을 최대화한다.
이는
$s_{t-1}$상태와 함께 WORKER가 취한$x_t$작업을 샘플링하여 근사할 수 있다.WORKER에 제공되는 보상은 다음과 같이 정의된다.
$$ r_t^I=\frac{1}{c} \sum_{i=1}^c d_{\cos }\left(f_t-f_{t-i}, g_{t-i}\right) $$ -
실제로는
$G_\theta$는 적대적 학습 전에 사전 학습이 필요하다.사전 학습 시 일관성을 유지하기 위해 MANAGER의 기울기를 통한 별도의 훈련 체계를 사용한다.
$$ \nabla_{\theta_m}^{\mathrm{pre}} g_t=-\nabla_{\theta_m} d_{\cos }\left(\hat{f}_{t+c}-\hat{f}_t, g_t\left(\theta_m\right)\right) $$$\hat{f}_t=\mathcal{F}\left(\hat{s}_t\right), \hat s_t, \hat s_{t + c}:$실제 텍스트의 상태
해당 수식은 앞에서 정의한 MANAGER 미분식에서
$Q_{\mathcal{F}}\left(s_t, g_t\right)$가$1$인 상태이다.사전 학습에 사용된 데이터는 모두 실제 문장이기 때문이다.
feature space에서 실제 문장 샘플의 전환을 모방하도록 학습된다.
MLE(Maximum Likelihood Estimation)를 통해 훈련된다.
학습 과정에서 $G_\theta$와 $D_\phi$는 번갈아가며 훈련된다.
생성망에서도 MANAGER와 WORKER는 번갈아가며 서로를 고정한 채 훈련된다.
분별망 $D_\phi$
$D_\phi:$ 파라미터가 $\phi$인 분별망
1. Scalar Guiding Signal $D_\phi(s)$ 제공
전체 문장 $s_T$가 생성된 후 생성망이 파라미터를 조정할 때 가이드 역할을 한다.
이 때, $D_\phi(s)$는 문장이 길어질수록 정보량이 적어지므로, 이를 해결하기 위해 추가적인 정보 $f_t$를 제공한다.
Guiding Signal(Leaked Features)
$$
D_\phi(s)=\operatorname{sigmoid}\left(\phi_l^{\top} \mathcal{F}\left(s ; \phi_f\right)\right)=\operatorname{sigmoid}\left(\phi_l^{\top} f\right)
$$
$s:$input. 생성된 문장.$\mathcal F:$CNN (특징맵 추출기)$f : D_\phi(s)$의 마지막 Layer에서의 feature vector(유출된 정보)$\phi_l^{\top}:$가중치 벡터
즉, $f$에 의해 Reward Value가 결정되기 때문에, 보상을 높이도록 feature(특징맵)을 뽑아야 한다.
LeakGAN에서는 Feature Extractor로 CNN을 활용하지만, LSTM이나 다른 신경망을 활용하여 구현할 수도 있다.
2. $f_t = s_t$에서의 features
$f_t$는 분별망이 분별을 위해서 쓰이는 정보이기도 하다.
따라서, 전역적으로 관리된다.
3. Learned Reward Function을 설정한다.
Black Box인 기존 RL 모델들과 대비된다.
-
text 분류를 위한 CNN 모델
num_filters (int): This is the output dim for each convolutional layer, which is the number of “filters” learned by that layer.
-
__init__def __init__(self, seq_len, num_classes, vocab_size, dis_emb_dim, filter_sizes, num_filters, start_token, goal_out_size, step_size, dropout_prob, l2_reg_lambda): super(Discriminator, self).__init__() self.seq_len = seq_len self.num_classes = num_classes self.vocab_size = vocab_size self.dis_emb_dim = dis_emb_dim self.filter_sizes = filter_sizes self.num_filters = num_filters self.start_token = start_token self.goal_out_size = goal_out_size self.step_size = step_size self.dropout_prob = dropout_prob self.l2_reg_lambda = l2_reg_lambda self.num_filters_total = sum(self.num_filters) #Building up layers **self.emb = nn.Embedding(self.vocab_size + 1, self.dis_emb_dim)** **self.convs = nn.ModuleList([ nn.Conv2d(1, num_f, (f_size, self.dis_emb_dim)) for f_size, num_f in zip(self.filter_sizes, self.num_filters) ])** **self.highway = nn.Linear(self.num_filters_total, self.num_filters_total)** #in_features = out_features = sum of num_festures self.dropout = nn.Dropout(p = self.dropout_prob) #Randomly zeroes some of the elements of the input tensor # with probability p using Bernouli distribution #Each channel will be zeroed independently onn every forward call **self.fc = nn.Linear(self.num_filters_total, self.num_classes)** -
highway
class Highway(nn.Module): #Highway Networks = Gating Function To Highway = y = xA^T + b def __init__(self, in_size, out_size): super(Highway, self).__init__() self.fc1 = nn.Linear(in_size, out_size) self.fc2 = nn.Linear(in_size, out_size) def forward(self, x): #highway = F.sigmoid(highway)*F.relu(highway) + (1. - transform)*pred # sets C = 1 - T g = F.relu(self.fc1) t = torch.sigmoid(self.fc2) out = g*t + (1. - t)*x return outt가 1이면 out = g
t가 0이면 out = x
t는 torch.sigmoid(self.fc2)에 의해 결정됨.
-
truncated_norm : 난수(절단된 정규분포)로 가중치 초기화에 사용
import torch from scipy.stats import truncnorm import torch.nn as nn import torch.nn.functional as F import numpy as np def truncated_normal(shape, lower=-0.2, upper=0.2): size = 1 for dim in shape: size *= dim w_truncated = truncnorm.rvs(lower, upper, size=size) w_truncated = torch.from_numpy(w_truncated).float() w_truncated = w_truncated.view(shape) return w_truncated -
forward
def forward(self, x): """ Argument: x: shape(batch_size * self.seq_len) type(Variable containing torch.LongTensor) Return: pred: shape(batch_size * 2) For each sequence in the mini batch, output the probability of it belonging to positive sample and negative sample. feature: shape(batch_size * self.num_filters_total) Corresponding to f_t in original paper score: shape(batch_size, self.num_classes) """ #1. Embedding Layer #2. Convolution + maxpool layer for each filter size #3. Combine all the pooled features into a prediction #4. Add highway #5. Add dropout. This is when feature should be extracted #6. Final unnormalized scores and predictions emb = self.emb(x).unsqueeze(1) convs = [F.relu(conv(emb)).squeeze(3) for conv in self.convs] # [batch_size * num_filter * seq_len] pooled_out = [F.max_pool1d(conv, conv.size(2)).squeeze(2) for conv in convs] # [batch_size * num_filter] pred = torch.cat(pooled_out, 1) # batch_size * sum(num_filters) highway = self.highway(pred) highway = torch.sigmoid(highway)* F.relu(highway) + (1.0 - torch.sigmoid(highway))*pred features = self.dropout(highway) score = self.fc(features) pred = F.log_softmax(score, dim=1) #batch * num_classes return {"pred":pred, "feature":features, "score": score} def l2_loss(self): W = self.fc.weight b = self.fc.bias l2_loss = torch.sum(W*W) + torch.sum(b*b) l2_loss = self.l2_reg_lambda * l2_loss return l2_loss
-
학습 기술
Bootstrapped Rescaled Activation
-
배경
SeqGAN의 적대적 훈련 과정에서,
$D$가$G$보다 너무 강한 경우 심각한 gradient 소멸 문제가 발생한다.즉, 파라미터를 갱신하기에 보상이 너무 작기 때문에
$G$에게 값을 넘기기 전에 스케일 조정이 필요하다.
RankGAN로부터 영감을 받은 rank 기반 방법
보상 행렬 : $R_{B\times T}$
-
다음 수식으로
$t$번째 열 벡터$R^t$의 스케일을 재조정한다.$$ R_i^t=\sigma\left(\delta \cdot\left(0.5-\frac{\operatorname{rank}(i)}{B}\right)\right) $$ -
$\text {rank}(i):$열 벡터에서 i번째 원소의 ranking -
$\delta :$rescale 작업의 smoothness를 조정하는 하이퍼 파라미터 -
$\sigma(\cdot) :$활성 함수(논문에서는 sigmoid)등간격 점수를 rank 기반으로 보다 효과적인 분포로 재구성한다.
장점
-
각 미니 배치에서 보상의 기대와 분산이 일정하다.
값을 안정시켜 수치형 분산에 민감한 알고리즘에 도움이 된다.
-
모든 ranking 방법과 동일하게, 모델 수렴을 가속화하는 gradient 소실 문제를 방지한다.
Interleaved Training
사전 훈련 후 전부 GAN으로 학습하는 대신 일부는 지도 학습(ex — MLE)으로, 일부는 적대적 학습(ex — GAN)을 적용한다.
ex) 1 epoch 지도 학습 + 15 epoch 적대적 학습
- GAN이 local minima를 제거하는 데 도움을 준다.
- mode collapse를 예방한다.
삽입된 지도 학습이 생성 모델에 대해 암시적 규제를 수행하여 MLE 결과로부터 너무 멀리 떨어지는 것을 방지한다.
Temperature Control
볼츠만 temperature $\alpha$.
탐험와 탐사의 균형을 맞추는 데 사용할 수 있는 요소
- 모델 훈련 시 높은 temperature 설정
- 샘플 생성을 위해 모델 적용 시 낮은 temperature 설정
Pseudo Code

필요한 요소
-
계층 구조 생성망
$G(θ_m, θ_w)$MANAGER와 WORKER로 구성
-
분별망
$D(φ)$이진 분류기
-
훈련 데이터 셋
시퀀스 데이터 집합
$S = {X_1:T}$
알고리즘 단계
-
파라미터 초기화
$G(θ_m, θ_w), D(φ)$를 랜덤 가중치$θ_m, θ_w, φ$로 초기화 -
사전 학습
-
$**D(φ)$사전 학습**$D(φ)$를 시퀀스 데이터 집합$S$를 양성 샘플로,$G$에서 생성된 시퀀스를 음성 샘플로 사용하여 사전 학습한다.이때,
$D(φ)$는 특징 추출기($\mathcal F$)와 출력 레이어(sigmoid)로 구성된다.$$ D_\phi(s)=\operatorname{sigmoid}\left(\phi_l^{\top} \mathcal{F}\left(s ; \phi_f\right)\right)=\operatorname{sigmoid}\left(\phi_l^{\top} f\right) $$ -
$**G(θ_m, θ_w)$사전 학습**$D(φ)$로부터 유출된 정보를 사용하여 학습한다.
-
-
사전 학습을 수렴할 때까지 번갈아 수행한다.
-
적대적 학습
-
생성망 단계 (g-steps)
-
$G(θ)$를 사용하여 시퀀스$Y_1:T$를 생성 -
각
$t$에 대해$D(φ)$로부터 유출된 정보$f_t$를 저장 -
$Q\left(f_t, g_t\right)=\mathbb{E}\left[r_t\right]$을 통해 Monte Carlo Search를 사용하여$Q(f_t, g_t)$를 얻어낸다. -
MANAGER로부터 계산된 방향
$g_t$를 얻는다. -
WORKER 매개변수
$θ_w, ψ$, softmax를 갱신한다.$$ \begin{aligned} & \nabla_{\theta_w} \mathbb{E}_{s_{t-1} \sim G}\left[\sum_{x_t} r_t^I \mathcal{W}\left(x_t \mid s_{t-1} ; \theta_w\right)\right] \\ = & \mathbb{E}_{s_{t-1} \sim G, x_t \sim \mathcal{W}\left(x_t \mid s_{t-1}\right)}\left[r_t^I \nabla_{\theta_w} \log \mathcal{W}\left(x_t \mid s_{t-1} ; \theta_w\right)\right] \end{aligned} $$ -
MANAGER 매개변수
$θ_m$을 갱신한다.$$ \nabla_{\theta_m}^{\mathrm{adv}} g_t=-Q\left(f_t, g_t\right) \nabla_{\theta_m} d_{\cos }\left(\mathcal{F}\left(s_{t+c}\right)-\mathcal{F}\left(s_t\right), g_t\left(\theta_m\right)\right) $$
-
-
분별망 단계 (d-steps)
-
현재
$G(θ_m, θ_w)$를 사용하여 음성 예제를 생성하고 주어진 양성 예제 S와 결합한다. -
k-epoch 동안
$D(φ)$를 훈련한다.$$ D_\phi(s)=\operatorname{sigmoid}\left(\phi_l \cdot \mathcal{F}\left(s ; \phi_f\right)\right)=\operatorname{sigmoid}\left(\phi_l, f\right) $$
-
-
-
LeakGAN이 수렴할 때까지 반복한다.
참고
Long Text Generation via Adversarial Training with Leaked Information