손실 함수, 확률적 경사 하강법, 수치 미분, 배치 모드, 미니 배치 모드, 패턴 모드, Local Minima, Global Minima, Optimizer
Gradient Descent(경사하강법)
자연 과학과 공학에서 오랫동안 사용해온 최적화 방법
손실 함수의 최적 해를 찾기 위한 방법
1차 근삿값 발견을 위한 최적화 알고리즘
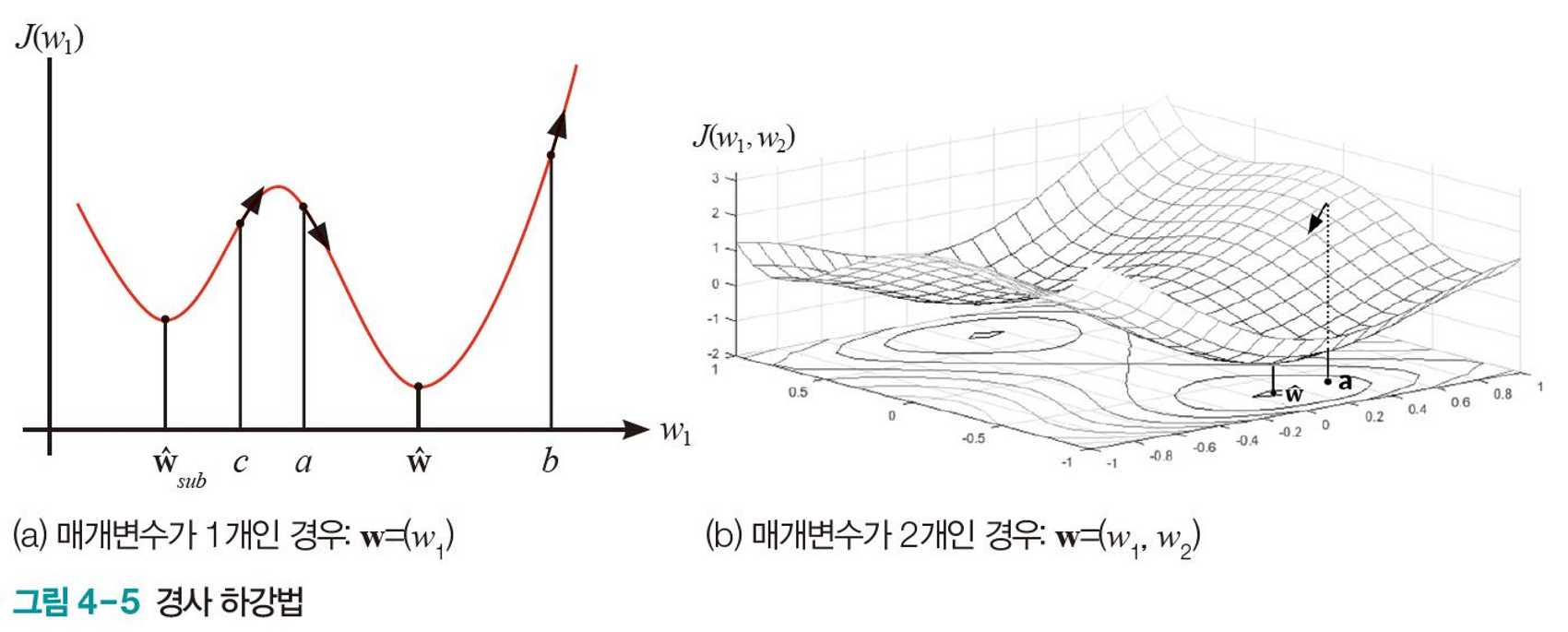
미분 값 $\partial J\over\partial w_1$의 반대 방향이 최적 해에 접근하는 방향이다.
따라서, 현재 가중치 $w_1$에 $-{\partial J\over\partial w_1}$을 더하면 최적 해에 가까워진다.
- 굳이 가까워질 필요 없이, 손실 함수를 미분해서 바로 극값을 찾으면 되지 않을까?
- 일반적으로 손실 함수가 매우 복잡하고 비선형적인 경우가 많기 때문에, 미분을 통해 극값을 계산하기 어렵다.
- 미분을 구현하는 것보다 경사 하강법으로 최솟값을 찾는 것이 더 효율적이다.
$$
w_{t+1} = w_t + \rho\left(-{\partial J\over\partial w_t}\right)
$$
$$
w \leftarrow w + \eta \left( -\frac{\partial L}{\partial w}\right)
$$
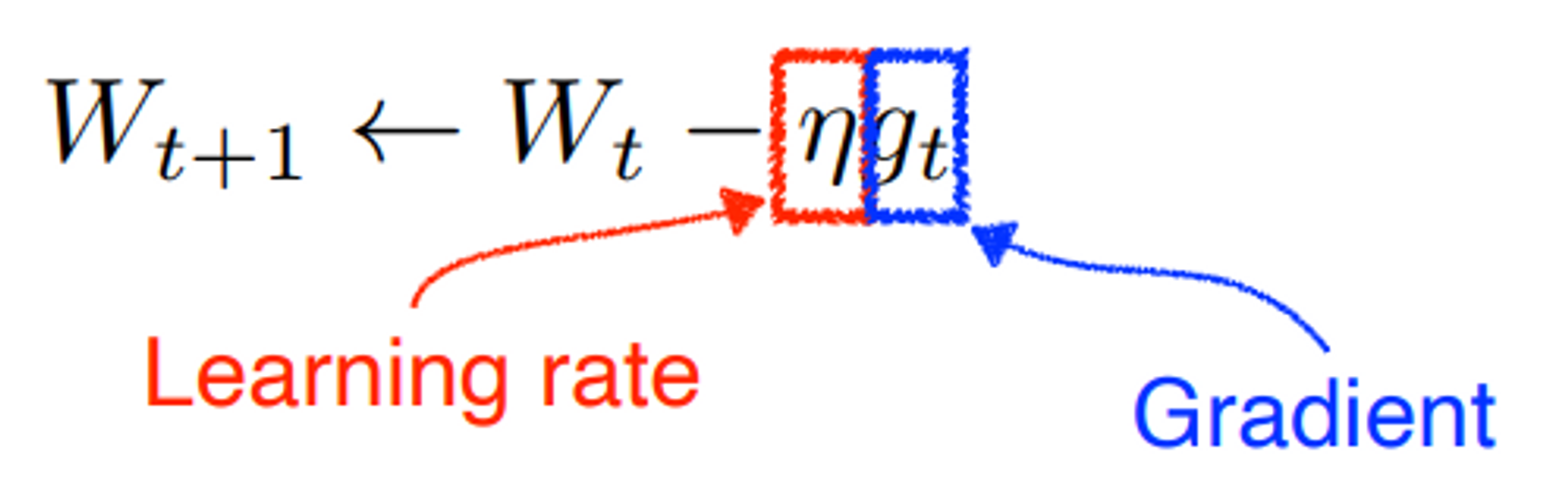
$J, L$: 손실 함수$\rho,\eta \text{(로, 에타)}$: 학습률$\leftarrow$: 업데이트를 의미한다.
표기는 다양하다.
매개변수가 여럿인 경우, 편미분으로 구한 기울기를 사용한다.
매개변수마다 독립적으로 미분한다.
$$
{\tt{w = w + \rho\left(\tt-\triangledown w\right)}}
\\
\tt\triangledown w = \left({\partial J\over\partial w_0},{\partial J\over\partial w_1},{\partial J\over\partial w_2},...,{\partial J\over\partial w_d}\right)
$$
적절한 학습률
학습률은 한번에 최적해를 향해 나아가는 거리를 의미한다.
학습률이 너무 낮다면, 수렴하는 데 시간이 너무 오래 걸리게 되고,
학습률이 너무 높다면, 최적해에 수렴하지 못하고 다른곳으로 발산하게 된다.
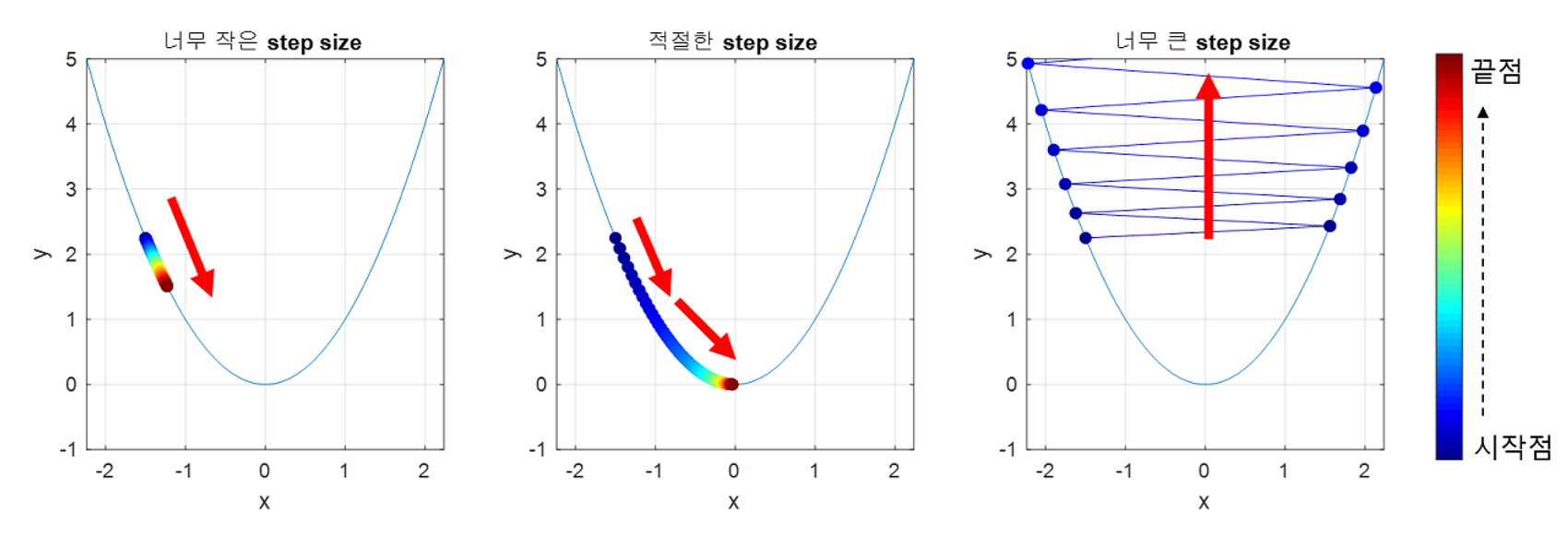
학습률을 적절히 조정하는 것이 매우 중요하다.
기계 학습의 경사 하강법
- 여러 측면에서 표준 경사 하강법과 다르다.
- 잡음이 섞인 데이터의 개입
- 방대한 매개변수
- 일반화 능력이 필요
- 기계 학습에서 최적 해를 찾는 것은 쉽지 않다.
- 정확률이 등락을 거듭하며 수렴하지 않는 문제
- 훈련 집합에서의 높은 성능이 테스트 집합에서의 성능으로 이어지지 않는 문제
경사 하강법 적용 방법
1. BGD: Batch Gradient Descent
-
배치 모드
틀린 샘플을 모은 다음 한꺼번에 매개변수 갱신한다.
한 epoch에 매개변수 갱신이 단 한번만 일어난다.
즉, 모든 샘플을 확인한 후, 최적의 방향으로 한 걸음 움직인다.
계산량이 많고 시간이 오래 걸린다.
2. SGD: Stochastic gradient descent(확률적 경사 하강법)
패턴 모드와 미니배치 모드의 경사하강법에는 랜덤 샘플링이 적용되기 때문에, Stochastic(확률적)이라는 수식어를 붙인다.
데이터를 무작위로 선택하여 훨씬 적은 데이터셋으로 평균값을 추정할 수 있다.
-
패턴 모드
샘플 하나에 대해 전방 계산을 수행하고 오류에 따라 바로 매개변수 갱신
패턴 별로 매개변수 갱신
epoch가 시작할 때 샘플을 뒤섞어 랜덤 샘플링 효과 발생
하나의 샘플을 확인한 후, 정보를 반영하여 바로 한 걸음 움직인다.
반복이 충분하면 SGD가 효과를 볼 수 있지만, 노이즈가 매우 심해 최저점을 찾지 못할 수도 있다.
-
미니 배치모드(딥러닝)
배치 모드와 패턴 모드의 중간
훈련 집합을 일정한 크기의 부분 집합으로 나눈 다음 부분 집합별로 처리한다.
부분 집합으로 나눌 때 랜덤 샘플링을 적용한다.
계산 속도가 훨씬 빠르다.
Local Minima에 빠지지 않고, Global Minima에 수렴할 가능성이 더 높다.
batch size
미니배치 모드에서의 매개변수.
배치 크기를 작게 두는 것이 Generalization 성능이 좋다.
배치사이즈가 너무 커지면 Sharp Minimum에 빠지게 된다.
Flat Minimum은 Generalization 성능이 좋다.
반대로, 배치사이즈가 작을수록 noise의 영향력이 커지므로 Sharp Minimum에서 탈출할 확률이 높다.
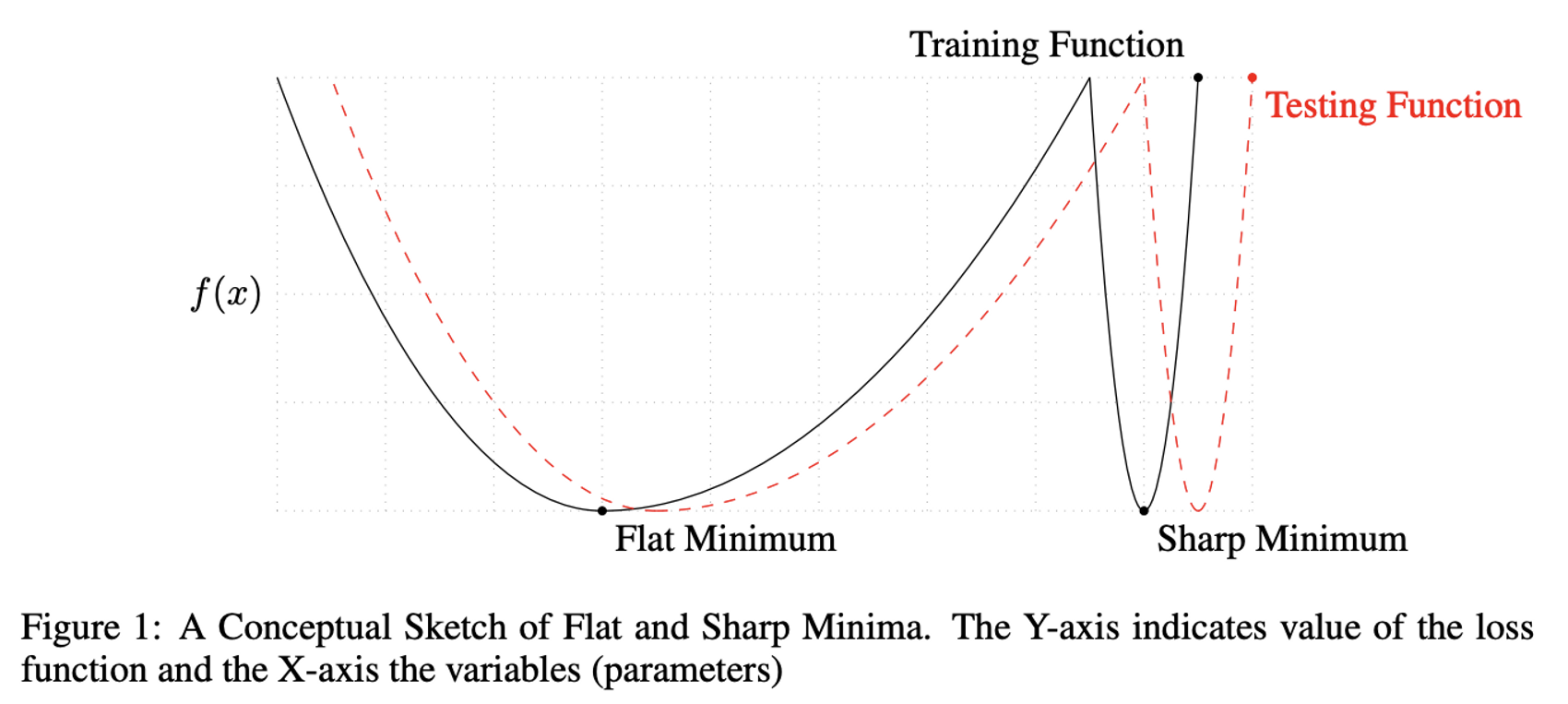
참고 논문 : On Large-batch Training for Deep Learning : Generalization Gap and Sharp Minima, 2017
Gradient Descent Algorithm에는 여러 문제점들이 존재하는데, 이를 해결한 Optimizer들이 등장한다.
-
Quiz.
$f(x,y,z)$의 그래디언트 벡터는?$f(x,y,z) = 9x^2 + 5y^3 - 3z$$\tt ans = (18x, 15y^2, -3)$