General Predictor에 Latent Factor Model을 추가한 모델.
Background
Factorization Machines
SVM과 Factorization Model의 장점을 결합한 FM을 처음 소개한 논문
등장 배경
딥러닝이 등장하기 이전 SVM이 가장 많이 사용됐다.
매우 희소한 데이터가 많은 CF 환경에서는 SVM보다 MF 계열의 모델이 더 높은 성능을 내왔다.
SVM과 MF의 장점을 결합할 수 없을까? ⇒ FM 탄생.
MF 기반 모델의 한계 ⇒ User-Item 행렬 기반
즉, 특정 데이터 포맷에 특화되어 있다.
$X:$ (유저, 아이템) → $Y:$ (rating)으로 이루어진 데이터에 대해서만 적용이 가능하다.
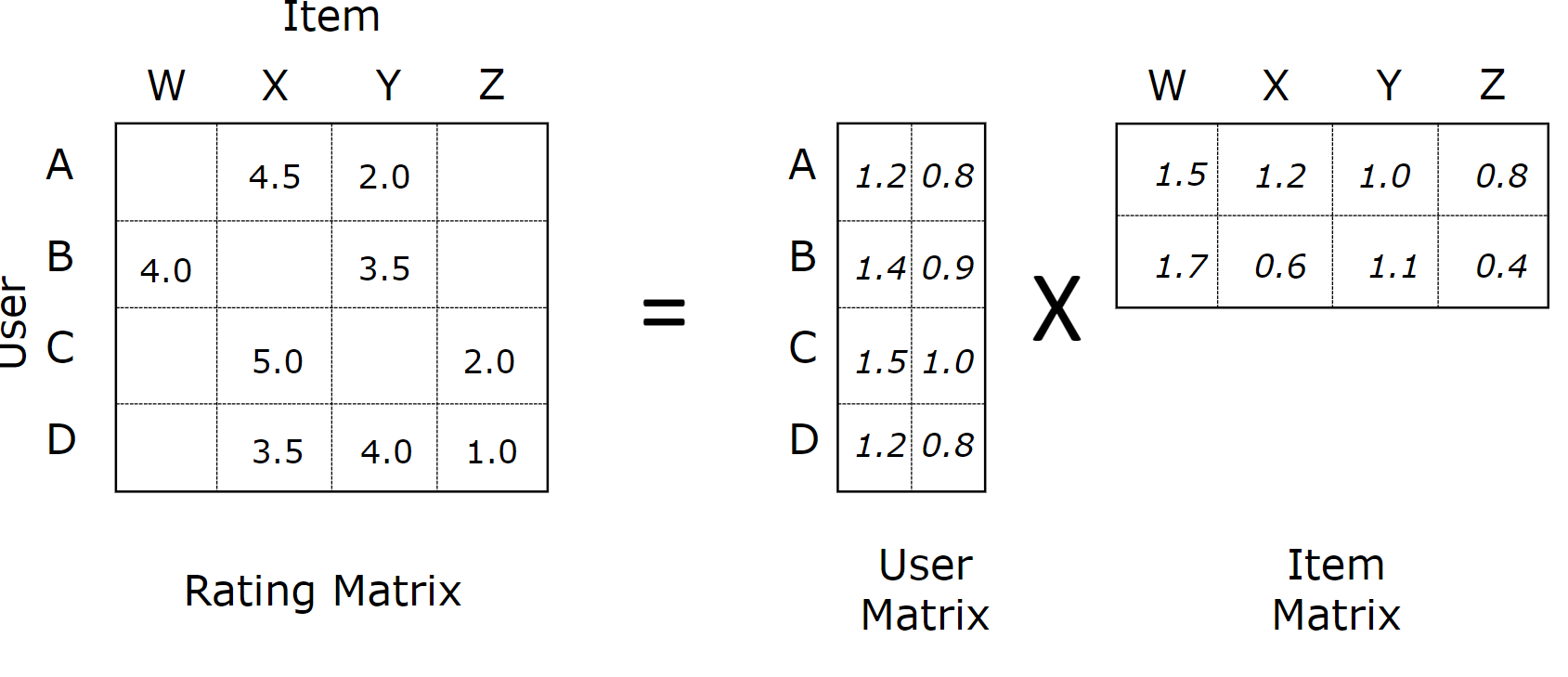
- 일반적인 데이터셋에 바로 적용 불가능
- User-Item 행렬 외의 정보를 활용하기 어렵다.
User-Item 행렬을 범용적인 형태로 변경했을 때의 문제점
- ML 모델에 사용되는 데이터 형태를 만들면 high sparsity 문제가 발생한다.
- 원활한 파라미터 학습이 어렵다.
- Feature간 상호작용을 반영하기 어렵다.
FM 공식
$$
\hat{y}(\mathrm{x})=w_0+\sum_{i=1}^n w_i x_i\blue{+\sum_{i=1}^n \sum_{j=i+1}^n\left\langle\mathrm{v}_i, \mathrm{v}_j\right\rangle x_i x_j}\\\\\\
w_0 \in \mathbb{R}, \quad w_i \in \mathbb{R}, \quad \mathrm{v}_i \in \mathbb{R}^k
$$
-
$\langle \cdot,\cdot \rangle:$두 벡터의 스칼라곱(dot product)$$ \left\langle\mathrm{v}_i, \mathrm{v}_j\right\rangle:=\sum_{f=1}^k \mathrm{v}_{i, f} \cdot \mathrm{v}_{j, f} $$
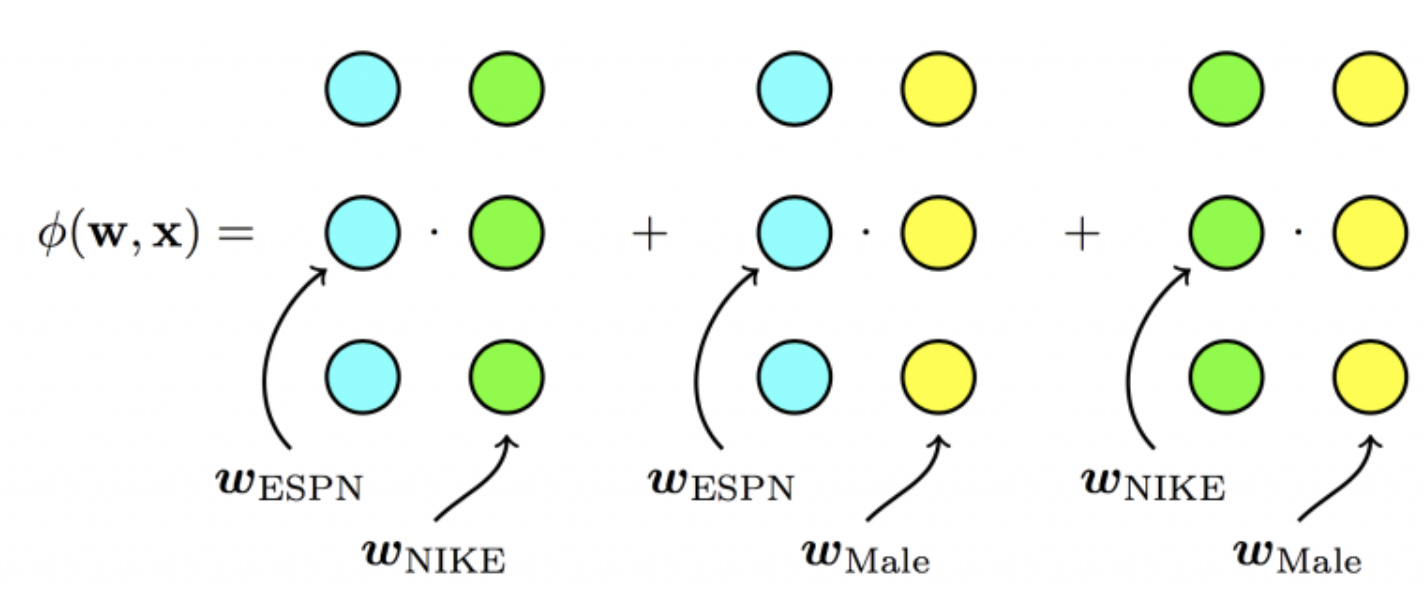
-
Logistic Regression에 두 Feature의 상호작용을 나타내는 Term이 추가된 형태
-
Logistic Regression
$$ \hat{y}(\mathrm{x})=w_0+\sum_{i=1}^n w_i x_i\\\\\\ w_0 \in \mathbb{R}, \quad w_i \in \mathbb{R} $$
-
-
Polynomial Model과 상호작용을 모델링하는 Term이 다르다.
-
Polynomial Regression
$$ \hat y(x)=\left(w_0+\sum_{i=1}^n w_i x_i{+\sum_{i=1}^n \sum_{j=i+1}^n w_{i j} x_i x_j}\right), \quad w_i, w_{i j} \in \mathbb{R} $$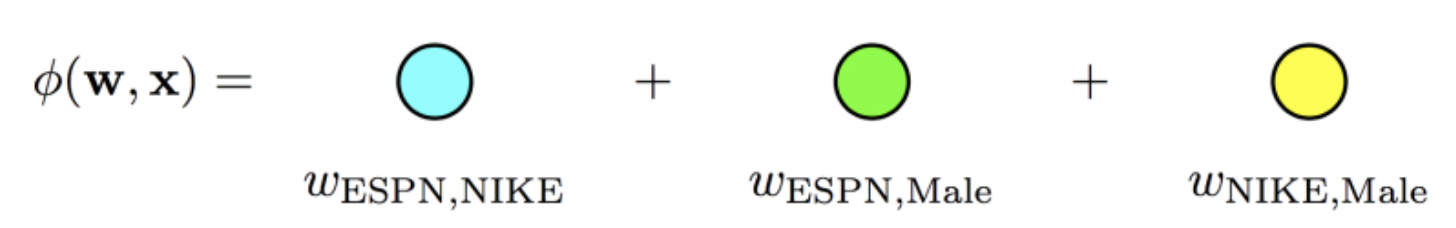
-
$x_ix_j$의 상호작용을 하나의 파라미터$(w_{ij})$로 나타낸 Polynomial에 비해,$\left\langle\mathrm{v}_i, \mathrm{v}_j\right\rangle$의 k차원의 Factorization 파라미터로 나타내 더욱 일반화시켰다.
-
FM의 활용
Sparse한 데이터셋에서 예측하기
유저의 영화에 대한 평점 데이터는 대표적인 High Sparsity 데이터
유저 - 아이템 매트릭스에서 다루던 Sparse Matrix와는 다른 의미
평점 데이터 = { (유저1, 영화2, 5), (유저3, 영화1, 4), (유저2, 영화3, 1), … }
일반적인 CF 문제의 입력 데이터와 같음
위의 평점 데이터를 일반적인 입력 데이터로 바꾸면, 입력 값의 차원이 전체 유저와 아이템 수만큼 증가
ex) 유저 수가 $U$명, 영화의 수가 $M$개일 때
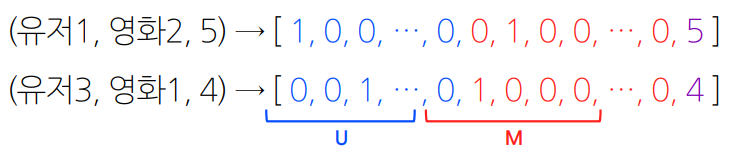
-
Sparse한 Feature들의 상호작용이 학습되는 방법
유저 A의 ST에 대한 평점 예측 →
$V_A, V_{ST}$가 FM 모델을 통해 학습되기 때문에 상호작용이 반영된다.$V_{ST}$— 유저 B,C의 영화 ST에 대한 평점 데이터를 통해 학습된다.유저 B,C는 영화 ST 외에 다른 영화도 평가한다.
$V_A$— 유저 B,C가 유저 A와 공유하는 영화 SW의 평점 데이터를 통해 학습한다.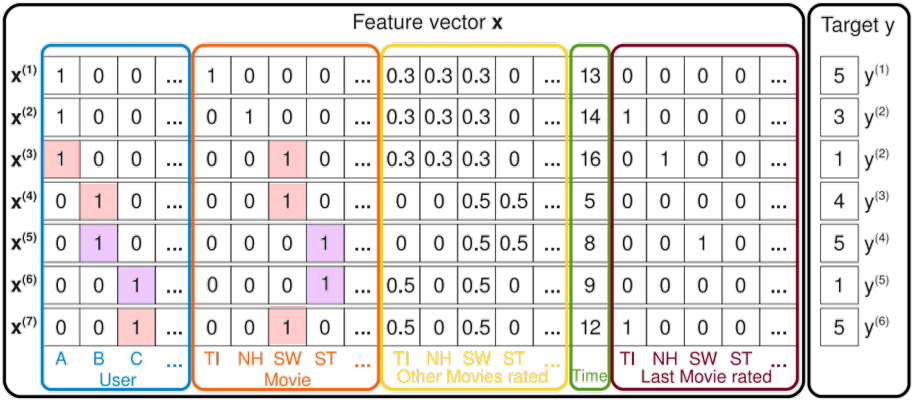
FM의 장점
vs. SVM
-
매우 sparse한 데이터에 대해서 높은 예측 성능을 보인다.
-
선형 복잡도
$(O(kn))$를 가지므로 수십 억 개의 학습 데이터에 대해서도 빠르게 학습한다.모델의 학습에 필요한 파라미터의 개수도 선형적으로 비례한다.
vs. Matrix Factorization
-
여러 예측 문제(회귀/분류/랭킹)에 모두 활용 가능한 범용적인 지도 학습 모델
-
일반적인 실수 변수(real-value feature)를 모델의 입력(input)으로 사용한다.
MF와 비교했을 때 유저, 아이템 ID 외에 다른 부가 정보들을 모델의 피쳐로 사용할 수 있다.
FM의 시간 복잡도
$$
\begin{aligned}& \tt\sum_{i=1}^n \sum_{j=i+1}^n\left\langle\mathbf{v}_i, \mathbf{v}_j\right\rangle x_i x_j \quad\quad \quad\quad\quad\quad\quad\quad{\Longrightarrow O(kn^2)} \\= & \frac{1}{2} \sum_{i=1}^n \sum_{j=1}^n\left\langle\mathbf{v}_i, \mathbf{v}_j\right\rangle x_i x_j-\frac{1}{2} \sum_{i=1}^n\left\langle\mathbf{v}_i, \mathbf{v}_i\right\rangle x_i x_i \\= & \tt\frac{1}{2}\left(\sum_{i=1}^n \sum_{j=1}^n \sum_{f=1}^k v_{i, f} v_{j, f} x_i x_j-\sum_{i=1}^n \sum_{f=1}^k v_{i, f} v_{i, f} x_i x_i\right) \\= & \tt\frac{1}{2} \sum_{f=1}^k\left(\left(\sum_{i=1}^n v_{i, f} x_i\right)\left(\sum_{j=1}^n v_{j, f} x_j\right)-\sum_{i=1}^n v_{i, f}^2 x_i^2\right) \\= & \tt\frac{1}{2} \sum_{f=1}^k\left(\left(\sum_{i=1}^n v_{i, f} x_i\right)^2-\sum_{i=1}^n v_{i, f}^2 x_i^2\right)\quad\quad{\Longrightarrow O(kn)}\end{aligned}
$$
어떻게 수식을 정리하여 시간복잡도를 줄일 수 있었나?
2중 반복문을 (1중 반복문)^2의 형태로 치환하여 계산을 줄였다.