개요
Field-aware Factorization Machines for CTR Prediction
- FM의 변형된 모델인 FFM을 제안하여 더 높은 성능을 보인 논문
FM은 예측 문제에 두루 적용 가능한 모델로, 특히 sparse 데이터로 구성된 CTR 예측에서 좋은 성능을 보인다.
Field-aware Factorization Machine (FFM)
-
FM을 발전시킨 모델
-
PITF 모델에서 아이디어를 얻었다.
PITF : Pairwise Interaction Tensor Factorization
MF를 3차원으로 확장시킨 모델
PITF에서는 (user, item, tag) 3개의 필드에 대한 클릭률을 예측하기 위해
(user, item), (item, tag), (user, tag) 각각에 대해서 서로 다른 latent factor를 정의하여 계산
⇒ 이를 일반화하여 여러 개의 필드에 대해서 latent factor를 정의한 것이 FFM
FFM의 특징
-
입력 변수를 필드(field)로 나누어, 필드별로 서로 다른 latent factor를 가지도록 factorize한다.
기존의 FM은 하나의 변수에 대해서 k개로 factorize했으나 FFM은 f개의 필드에 대해 각각 k개로 factorize한다.
-
Field
-
같은 의미를 갖는 변수들의 집합으로 설정
유저: 성별, 디바이스, 운영체제
아이템: 광고, 카테고리
컨텍스트: 어플리케이션, 배너
-
모델을 설계할 때 함께 정의
-
-
CTR 예측에 사용되는 피쳐는 이보다 훨씬 다양하다.
보통 피쳐의 개수만큼 필드를 정의하여 사용할 수 있다.
FFM 공식
$$
\begin{gathered}\hat{y}(\mathrm{x})=w_0+\sum_{i=1}^n w_i x_i+\sum_{i=1}^n \sum_{j=i+1}^n\left\langle\mathrm{v}_{i, f_j}, \mathrm{v}_{j, f_i}\right\rangle x_i x_j \\w_0 \in \mathbb{R}, \quad w_i \in \mathbb{R}, \quad \mathrm{v}_{i, f} \in \mathbb{R}^k\end{gathered}
$$
$$
\begin{gathered}\hat{y}(\mathrm{x})=w_0+\sum_{i=1}^n w_i x_i+\sum_{i=1}^n \sum_{j=i+1}^n\left\langle\mathrm{v}_i, \mathrm{v}_j\right\rangle x_i x_j \\w_0 \in \mathbb{R}, \quad w_i \in \mathbb{R}, \quad \mathrm{v}_i \in \mathbb{R}^k\end{gathered}
$$
FM은 k차원의 파라미터를 $v_i$와 $v_j$가 내적이 된 형태로 상호작용을 표현하는 반면,
FFM은 $x_i$에 대응되는 파라미터가 $v_i$가 아니라, $v_{i,f_j}$가 된다.
즉, field $(f_i)$별로 Factorization 파라미터가 정의된다.
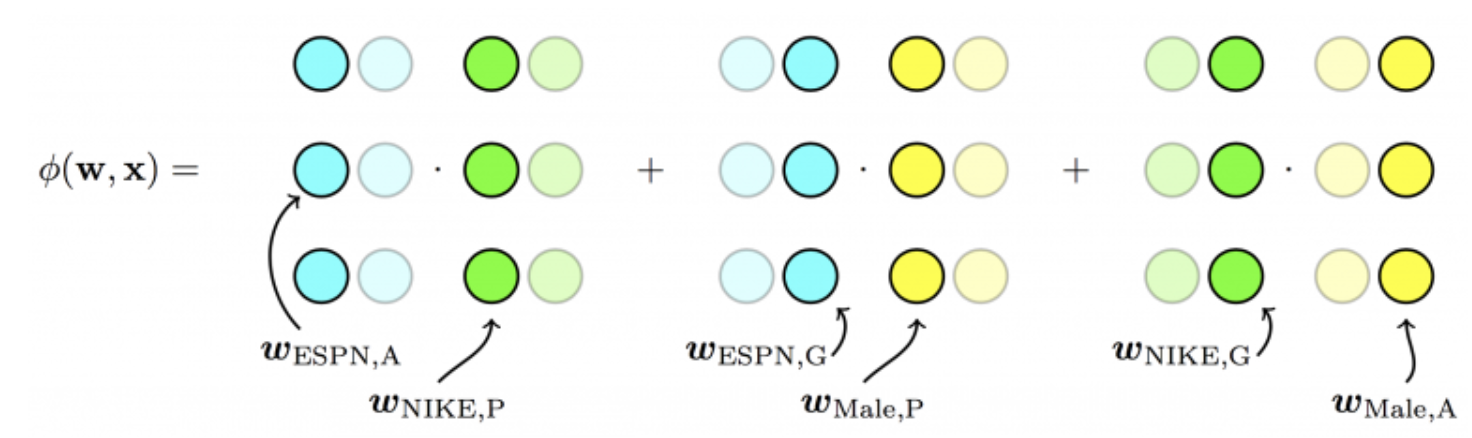
ex) 광고 클릭 데이터가 존재하고 사용할 수 있는 feature가 총 세 개(Publisher, Advertiser, Gender)일 때,
| Cliked | Publisher (P) | Advertiser (A) | Gender (G) |
|---|---|---|---|
| Yes | ESPN | Nike | Male |
-
FM
필드가 존재하지 않는다.
하나의 변수에 대해 factorization 차원
$(k)$만큼의 파라미터를 학습한다.$$ \hat{y}(\mathrm{x}) =w_0+w_{\mathrm{ESPN}}+w_{\mathrm{Nike}}+w_{\text {Male }}+{\mathrm{v}_{\mathrm{ESPN}} \cdot \mathrm{v}_{\mathrm{Nike}}\\ +\mathrm{v}_{\mathrm{ESPN}} \cdot \mathrm{v}_{\text {Male }}+\mathrm{v}_{\mathrm{Nike}} \cdot \mathrm{v}_{\text {Male }}} $$ -
FFM
각각의 feature를 필드 P,A,G로 정의
하나의 변수에 대해 필드 개수
$(f)$와 factorization 차원$(k)$의 곱$(=fk)$만큼의 파라미터를 학습한다.$$ \hat{y}(\mathrm{x}) =w_0+w_{\mathrm{ESPN}}+w_{\mathrm{Nike}}+w_{\text {Male }}+{\mathrm{v}_{\mathrm{ESPN}, \mathrm{A}} \cdot \mathrm{v}_{\mathrm{Nike}, \mathrm{P}}\\ +\mathrm{v}_{\mathrm{ESPN}, \mathrm{G}} \cdot \mathrm{v}_{\text {Male,P }}+\mathrm{v}_{\mathrm{Nike}, \mathrm{G}} \cdot \mathrm{v}_{\mathrm{Male}, \mathrm{A}}} $$
FFM의 필드 구성
Categorical Feature
FM

FFM
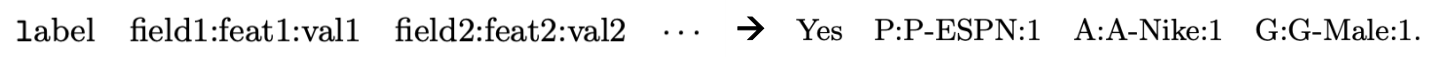
Numerical Feature
실수도 반드시 특정 필드에 속해야 한다.
-
dummy field
numeric feature 한 개당 하나의 필드에 할당하고 실수 값을 사용
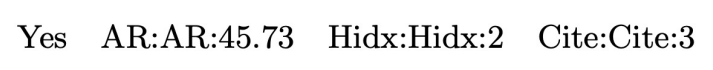
field가 크게 의미를 갖지 않는다.
-
discretize
numeric feature를 n개의 구간으로 나누어 이진 값을 사용하고, n개의 변수를 하나의 필드에 할당한다.

FM / FFM 성능 비교
LR에 비해 FM, FFM의 성능이 더 낫다.
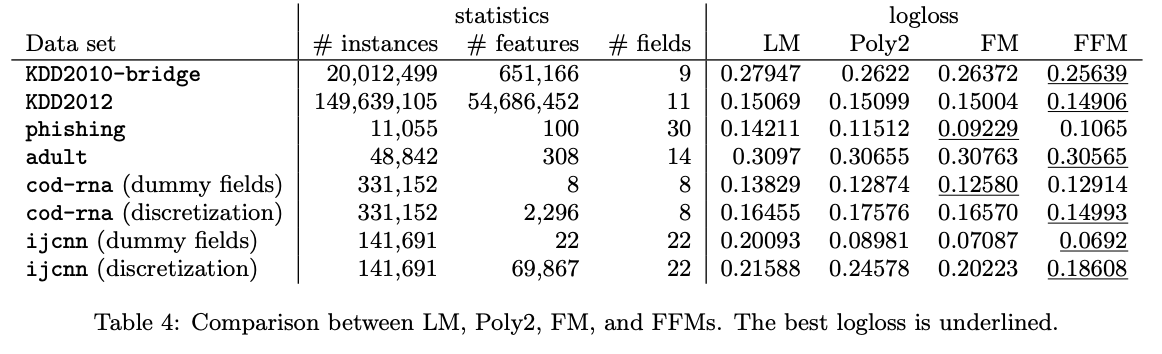
필드를 사용하는 것이 적절하지 않은 데이터셋의 경우 FFM보다 FM이 성능이 더 잘나온다.