-
Word2Vec을 학습하는 방법 중 하나.
-
앞뒤의 단어를 통해 중앙의 단어를 예측하는 방법
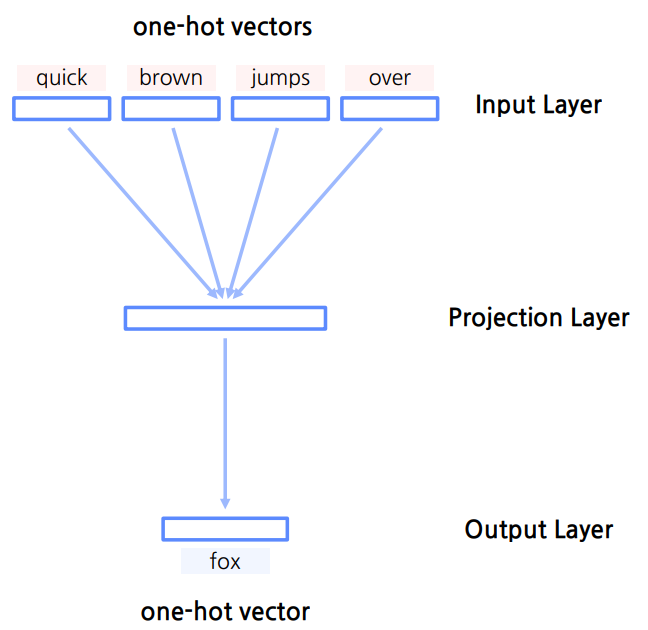
- input — quick, brown, jumps, over
- output — fox
단어를 예측하기 위해 앞뒤로 몇 개의 단어(n)를 사용할지 정한다.
-
Multi-Class Classification
Input을 통해 One-Hot Vector의 각 원소가 0인지 1인지 예측한다.
학습 파라미터
-
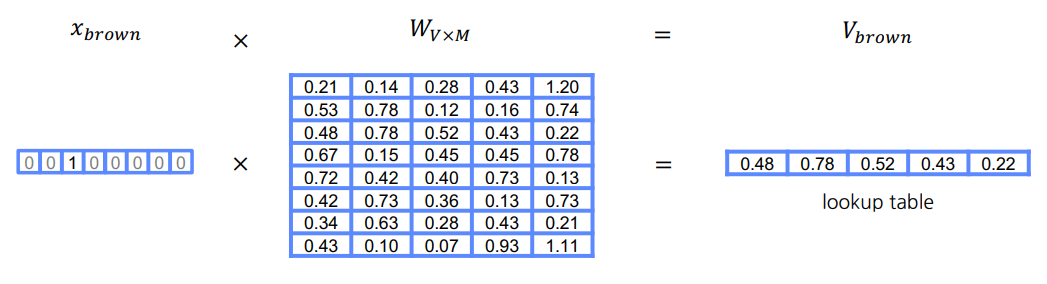
$W_{V\times M}$: One-Hot Vector을 임베딩 벡터로 변환하는 행렬$V$: 단어의 총 개수(One-Hot Vector의 크기)$M$: 임베딩 벡터의 크기
-
$W'_{M\times V}$: 임베딩 벡터를 One-Hot Vector의 길이로 변환하는 행렬
학습과정
Input Layer
- 주변의 단어를 One-Hot Vector로 입력받는다.
- 입력받은 One-Hot Vector를 임베딩 벡터로 변환한다.(
$W_{V\times M}$)
Projection Layer
- 변환된 임베딩 벡터들을 평균내어 임베딩 벡터
$v$를 구한다. → Word2Vec
-
임베딩 벡터
$v$를 One-Hot Vector와 동일한 크기로 변환한다.($W'_{M\times V}$)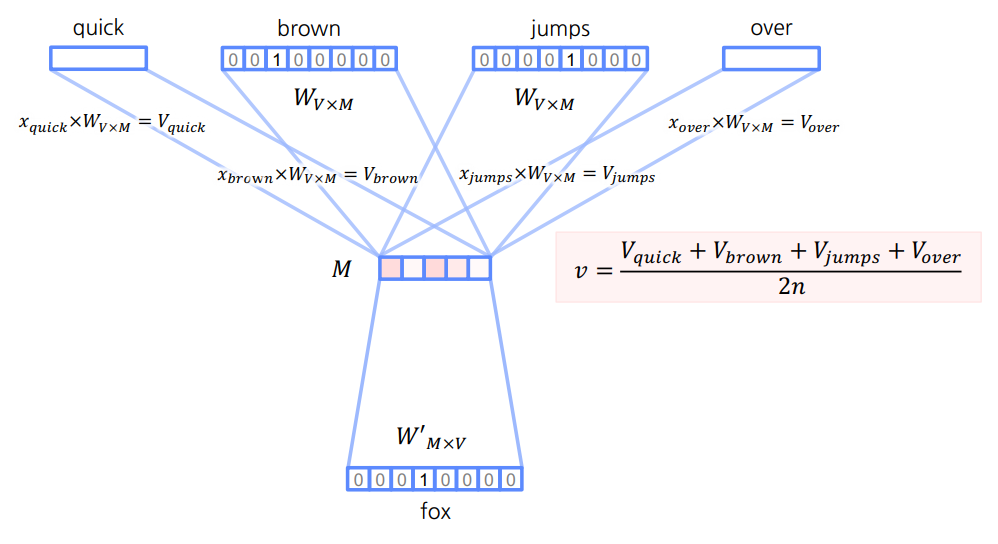
- 변환된 벡터
$z$를 Output Layer로 보낸다.
Output Layer
-
Softmax 함수를 통해 벡터
$z$를 확률 벡터로 변환한다. -
출력(
$\hat y$)을 평가하기 위해 중앙 단어의 One-Hot Vector($y$)와 CE를 계산한다.