1. 프로젝트 개요
-
개요
본 프로젝트에서는 소비자들의 책 구매 결정에 도움을 주기 위해 개인화된 상품을 추천하는 문제를 해결하였습니다.
본 프로젝트에서는 크게 세 가지 작업을 수행하였습니다.
- 주어진 데이터셋을 바탕으로 데이터의 내용을 분석하고 시각화하는 과정을 통해 인사이트를 도출하였습니다.
- 주어진 모델 예제들을 변형하고 조합하여 다양한 모델에 대한 성능을 실험하였습니다.
- 앞서 명시한 작업들을 통해 최고 성능을 내는 모델을 발굴하였습니다.
본 프로젝트를 수행하면서 부스트코스 RecSys 트랙에서 학습하였던 머신러닝/딥러닝 모델을 이해하고 이를 PyTorch 구현하면서 실생활 문제에 적용하는 경험을 하였습니다.
-
활용 장비 및 재료(개발 환경, 협업 tool 등)
- 로컬 환경:
Windows,Mac - 서버:
Linux (Tesla V100) - 협업 툴:
Slack,Notion,Github - 사용 버전:
Python == 3.8.5,Pandas == 2.0.0,Torch == 1.7.1
- 로컬 환경:
-
프로젝트 구조 및 사용 데이터셋의 구조
본 프로젝트에서 활용된 데이터셋은 크게 세 가지 하위 데이터셋으로 나눌 수 있었습니다.
- 📚 책과 관련된 정보를 저장한 데이터셋 (books.csv) - 149,570건의 데이터
- 👤 소비자와 관련된 정보를 저장한 데이터셋 (users.csv) - 68,092명의 데이터
- 🔢 소비자가 실제로 부여한 평점을 저장한 데이터셋 (ratings.csv) - 306,795건의 데이터
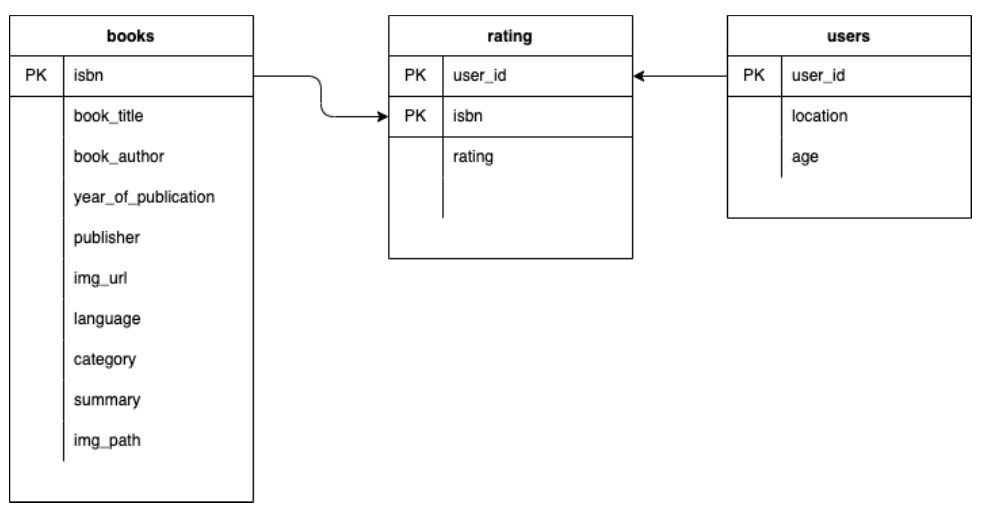
사용 데이터셋의 구조
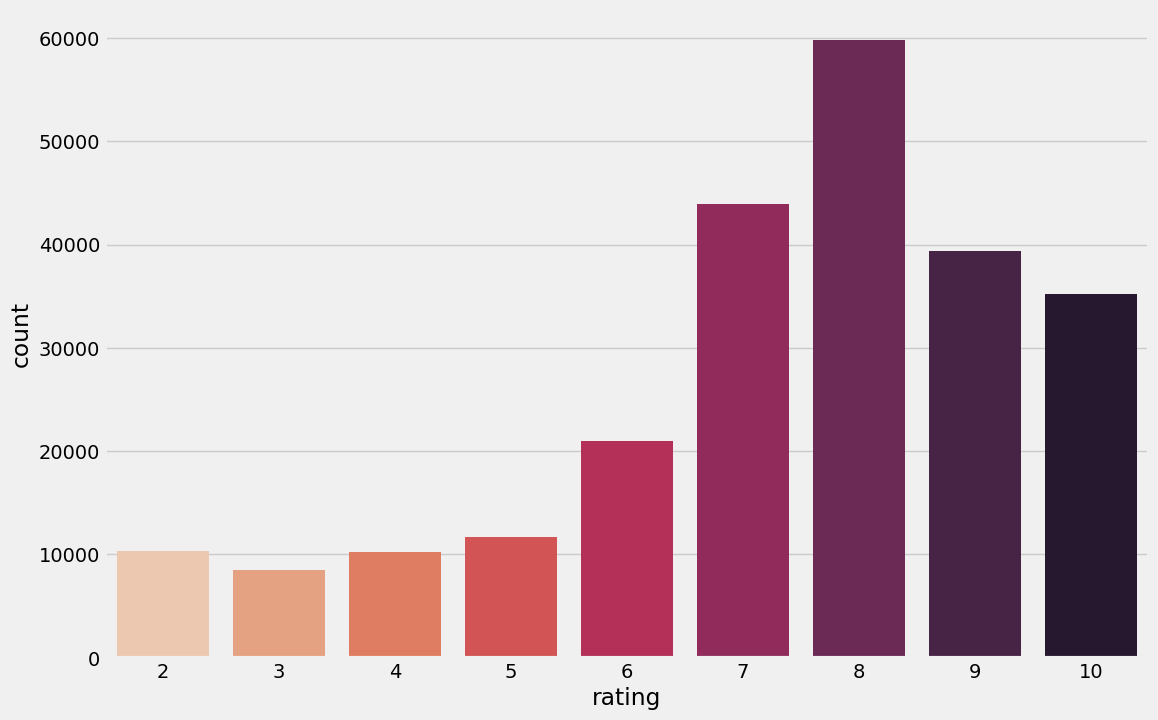
train_ratings의 rating 분포
2. 프로젝트 팀 구성 및 역할
| 이름 | 역할 |
|---|---|
| 김지연_T5062 | 데이터 EDA (분석 및 시각화), 데이터 전처리, 하이퍼 파라미터 튜닝, 피처 엔지니어링 |
| 음이레_T5134 | 데이터 전처리, early stop 적용, CNN_FM, DeepCoNN에 dropout 적용, MLP activation function 선택지 추가 |
| 오승민_T5126 | 프로젝트 관리, 데이터 EDA 및 결측치 산입(Mice), 후처리, Bagging(Random Forest), Boosting(LGBM Regressor) 모델 튜닝, 데이터 시각화, 모델 앙상블 |
| 조재오_T5204 | 데이터 EDA & 전처리, K-Fold 구현, 데이터 분포 분석, 후처리(Post-processing) |
| 윤한나_T5133 | 베이스라인 모델 실험, 데이터 전처리, 데이터 시각화, CatBoostRegressor , XGBRegressor모델 튜닝, 모델 앙상블 |
3. 프로젝트 수행 절차 및 방법
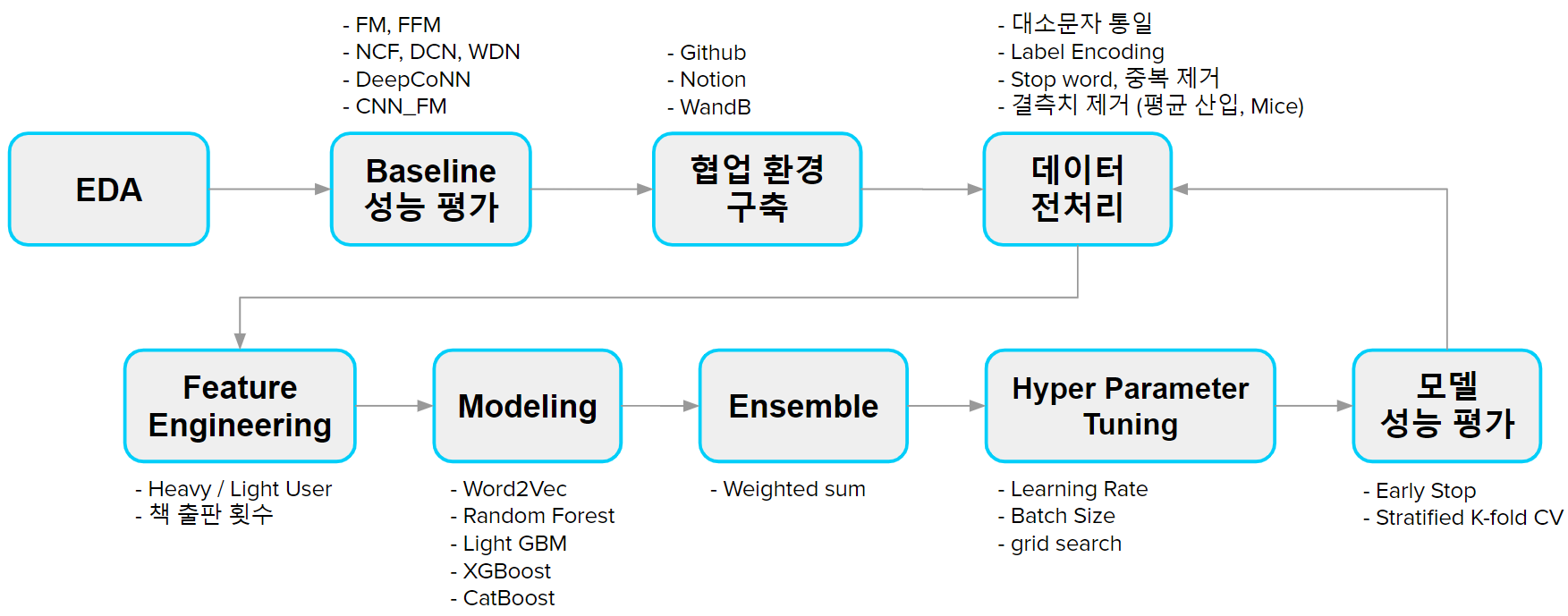
4. 프로젝트 수행 결과
-
순위 - 최종 순위 Public 7위 (RMSE: 2.1207) / Private 7위 (RMSE: 2.1159)


-
탐색적 분석 및 전처리
- 특수문자 및 중복 제거
- location 변수의 특수 문자를 제거하고, category 변수의 대소문자를 통일하여 중복을 제거하였습니다.
- Label Encoding
- CatBoostRegressor의 경우, 수치형 데이터인 age 변수를 범주화하여 사용하였습니다.
- 결측치 제거
- location_city가 null 값이 아닐 때, location_state와 location_country가 결측치인 경우, city를 기준으로 결측치를 채웠습니다.
- book_title이 null이 아닐 때, 책 제목이 같지만 language와 category가 결측치인 경우, book_title을 기준으로 결측치를 채웠습니다.
- Summary
- 불용어를 제거하고 word2vec 임베딩을 생성하였습니다.
- Feature Engineering
- 상위 카테고리 변수 추가: 5번 이상 등장한 카테고리의 경우로 이루어진 상위 카테고리 변수를 추가하였습니다.
- Heavy User / Light User: 책을 읽은 횟수가 5권 이상인 유저들을 Heavy User, 나머지 유저들을 Light User로 구분하는 변수를 추가하였습니다.
- 책 출판 횟수: 같은 책 제목의 isbn의 개수(출판 횟수) 변수를 추가하였습니다.
- 필드 생략
- Feature importance 분석에서 city/state field가 country field에 비해 높은 중요도를 가지고 있다는 결과가 나옴에 따라, 도서 선택에 도시/주보다 국가가 더 높은 연관성을 가질 거라는 직관과 충돌하여 의문을 가졌습니다.
- 이후 city/state field를 누락하고 location 정보를 country만 사용한 결과 성능 향상을 얻었습니다.
- 특수문자 및 중복 제거
-
모델 개요
실험에 사용한 모델들은 다음과 같습니다.
-
CARs(ML)
- FM
- FFM
-
CARs(DL)
- NCF
- DCN
- WDN
- CNN_FM - 이미지 데이터 추가 활용
- DeepCoNN - Summary 데이터 추가 활용
-
Bagging
- RandomForest
-
Boosting
- LGBM
- XGBoost
- CatBoost
-
3. 모델 선정 및 분석
-
최종 모델 선정 기준 / 앙상블 등
-
FM
-
Context-Aware Recommendation System 계열 ML Model
General Predictor + Latent Factor Model
-
RMSE : 2.354
-
성능이 가장 잘 나온 CatBoostRegressor와 예측 분포가 가장 다른 모델을 앙상블 해야 극단적인 값들이 중화되어 robust한 결과가 나올 것이라고 가정하였고, CatBoostRegressor와 가장 결과 예측 분포가 상이한 결과를 보였던 FM을 앙상블하여 RMSE 2.1299 → 2.1222로 큰 성능 향상 효과를 보였습니다.
-
-
DeepCoNN
- 텍스트 데이터 처리를 하는 딥러닝 모델로, 단일 모델의 성능은 RMSE 2.2228이었습니다.
- summary는 책의 내용을 나타내는 feature이기 때문에 책의 평점을 결정하는 데 유의미할 것이라고 가설을 세우고 실험하였고, 최종적으로 Deep_CoNN을 앙상블 모델에 포함하였습니다.
-
CatBoostRegressor
- 딥러닝 기반의 모델이 아닌 Decision Tree 기반의 모델로, 결측치가 존재하는 데이터에서 상대적으로 좋은 성능을 보였습니다.
- 주어진 데이터셋에서 age와 year_of_publication 변수를 제외한 모든 변수들이 범주형 데이터로 구성되어 있어, Boosting 기반의 회귀모델이며 범주형 데이터를 처리하는 데 강한, CatBoostRegressor를 사용하게 되었습니다.
- user embedding과 book embedding을 추가하고, train 데이터의 rating 분포가 imbalance하기 때문에 rating을 비율대로 나누어 train과 valid set을 분리하는 Stratified 10 K-Fold 방식을 사용하여 RMSE 2.1997 → 2.1306으로 성능 향상을 확인하였습니다.
- Optuna를 사용해 하이퍼 파라미터를 튜닝하여 RMSE 2.1306 → 2.1299로 성능 향상을 확인하였습니다.
-
앙상블 (simple-weighted ensemble사용)
-
Train의 분포와 결과 비교하며 weighted sum을 적용하였습니다.
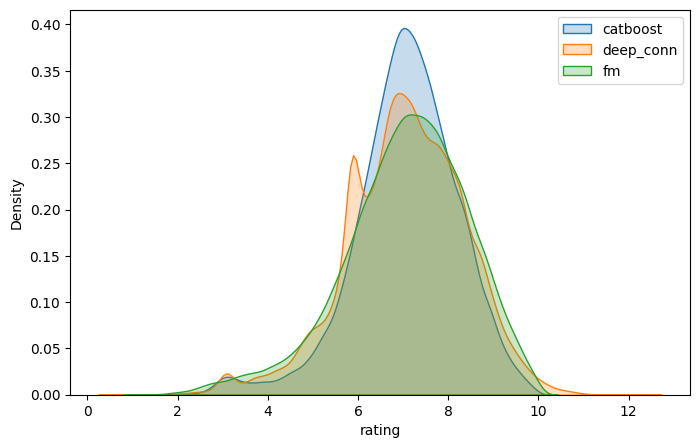
CatBoostRegressor, DeepCoNN, FM 모델의 결과 분포
-
최종적으로, CatBoostRegressor +Deep_CoNN + FM 을 7:1:2의 비율로 가중치를 주어 앙상블함 → RMSE 2.1159(private 기준)으로 7등을 달성하였습니다.
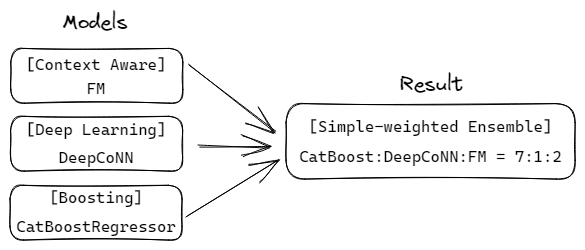
최종 Architecture - CatBoostRegressor + DeepCoNN + FM
-
-
모델 평가 및 개선, 후처리
-
Stratified K-fold
Baseline 및 여러 Boosting 계열 모델에 Stratified K-fold CV를 적용하여, 약간의 RMSE 개선과 모델의 일반화 성능을 향상시켰습니다.
-
Data Visualization
제출 횟수가 부족한 상황에서 모델별 성능을 파악하기 위해 모델의 결과물인 Submission.csv 파일의 Rating 분포를 고려했습니다.
RMSE가 내리는 상황에 데이터의 분포를 파악한 후, 데이터의 분포를 고려하여 개선 방향을 효과적으로 판단할 수 있었습니다.
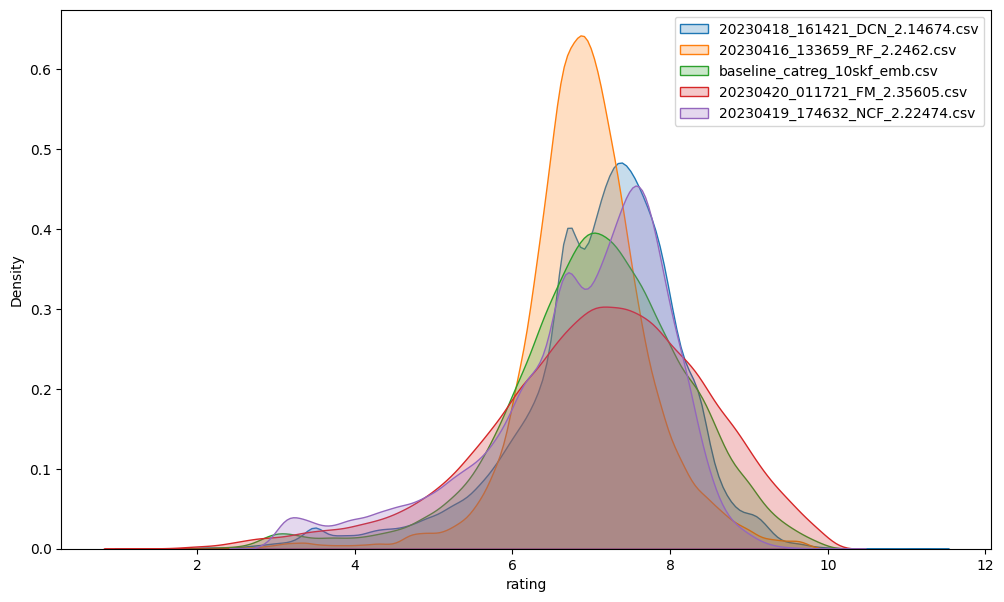
-
Post Processing
평점 예측 결과가 1~10의 범위를 초과하는 값들을 각각 1, 10으로 조정해주어 성능을 향상시켰습니다.
-
-
시연 결과
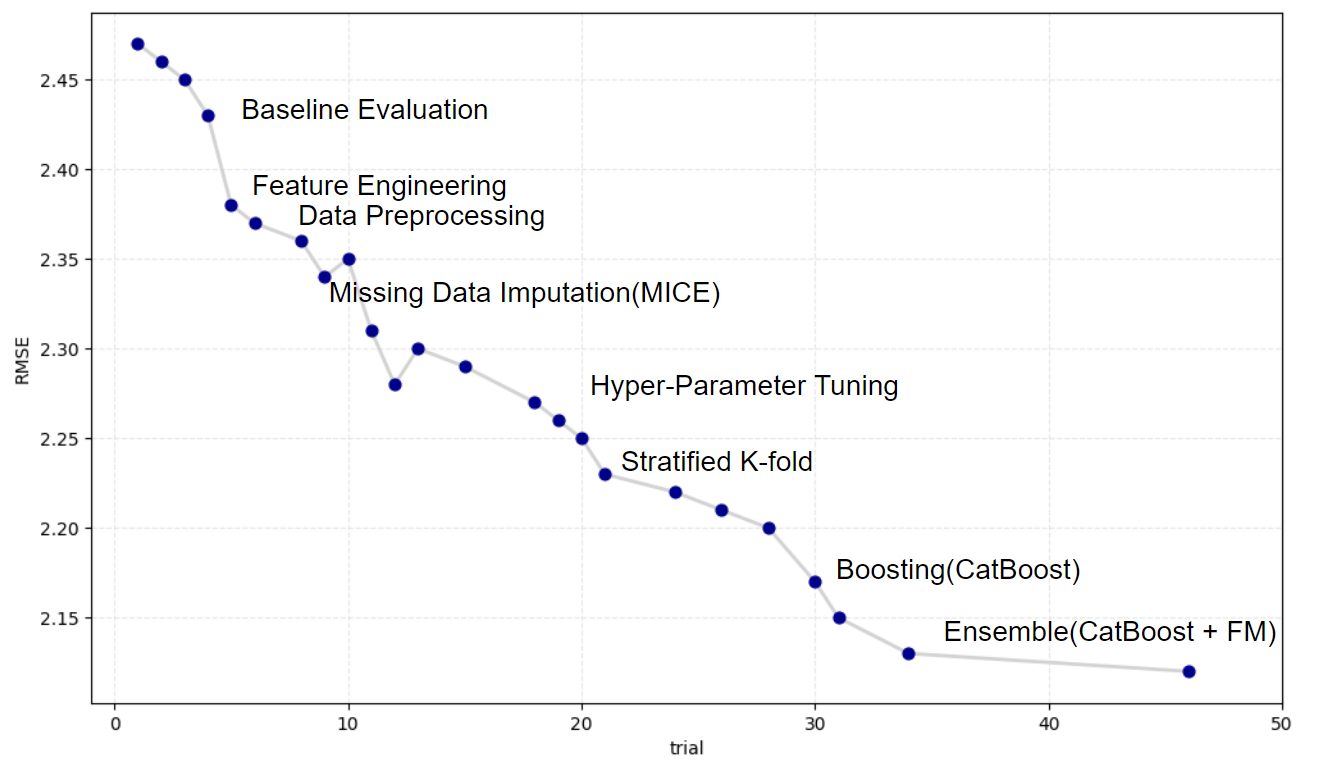
프로젝트 진행 흐름에 따른 성능 추이
5. 자체 평가 의견
- 배운 점
- 데이터셋 EDA 및 전처리를 통해 데이터를 정제하는 경험을 쌓을 수 있었습니다.
- 모델과 그 조합을 실험하며 성능의 증감 결과에 따른 이유를 추론하는 과정에서 부스트코스 학습 내용에 대해 더 깊이 이해할 수 있었습니다.
- 아쉬운 점
- 하루 10회의 리더보드 제출 권한을 충분히 활용하지 못한 점이 아쉬움으로 남습니다.
- 단일 모델에 집중하다가 Ensemble 실험을 충분히 하지 못한 점이 아쉽습니다.
- 시도할 점
- WandB를 적극적으로 활용하여 파라미터를 조율해보고 싶습니다.
- Github를 통한 협업을 보다 유연하게 진행하고 싶습니다.
- Weighted ensemble 외 다양한 ensemble을 시도하고 싶습니다.
개인 리포트
Team
- Notion 기록을 통해 서로 수행하는 작업에 대한 공유가 잘 됐다.
- 발생한 문제점들을 빠르게 공유하고 처리했다.
- 역할 분담은 없었으나 서로 배려하는 마음으로 대회가 잘 진행됐다.
- 모델 구현 일정을 제대로 확정 짓지 않아 작업이 늦어져 마지막에 제출 횟수가 많이 모자랐다.
Personal
-
Project Management — 팀원들에게 Git 활용법을 전파했다.
-
EDA 및 앙상블 모델 선택 — FM
대회 데이터셋이 정형데이터라는 점을 고려했을 때, ML계열을 앙상블에 활용해야 전체 성능이 잘 나올 것이라 짐작했다.
이를 위해 대회를 시작하자마자 FM 모델의 성능을 개선하는 것에 집중했으며, 결과적으로 최종 제출물에도 개선한 FM모델이 포함될 수 있었다.
-
활용한 모델 — FM, FFM, DeepCoNN, WDN, DCN, CNN_FM
-
Hyper Parameter Tuning — Batch_size, LR, Layer 개수, Dropout 등 조절
-
데이터 전처리 — Mice
-
Boosting 적용 — Light GBM Regressor
결측치에 약한 LGBM 모델의 성능을 높이기 위해 MI 모듈 MICE를 접목했다.
-
Bagging 적용 — Random Forest Regressor
-
Data Visualization
대회 마지막날 제출 횟수가 부족한 상황에서 모델별 성능을 파악하기 위해 모델의 결과물인 Submission.csv 파일의 Rating 분포를 고려했다.
RMSE가 내리는 상황에 데이터의 분포를 파악한 후, 데이터의 분포를 고려하여 개선 방향을 효과적으로 판단할 수 있었다.
-
Ensemble — 모델들의 성능과 데이터의 분포를 고려하며 sw 앙상블을 수행했다.
한계 및 교훈
-
모델 성능에 대해 단편적인 정보만 활용한 것
다양한 모델 평가 Metric을 활용해야겠다.
-
배움보다는, 대회 성적에 더 집중한 것
Hyper Parameter Tuning보다는, 모델 자체에 집중하여, 코드를 수정하고 구조를 변경해보자.
-
Baseline의 구조를 유지하고자 노력한 것
Baseline의 형태를 고집할 필요는 전혀 없다.
오히려 Baseline의 흐름을 벗어던진 후 Baseline을 완벽하게 이해할 수 있었다.
-
시간 분배를 제대로 하지 못한 것
LGBM의 성능개선을 미루다가 마지막 날의 제출 수가 부족하여 성능을 제대로 파악하지 못했다.
일의 우선순위를 제대로 설정한 후, 우선순위에 맞게 일을 처리하자.
다음 프로젝트에서 시도해보고 싶은 점
- Hybrid Model을 구현해보기.
- Valid Loss 뿐만 아니라 더 다양한 Metric으로 모델을 평가하기.
- 더 나은 방법으로 Hyper Parameter Tuning을 수행하기.
- Baseline에 얽매이지 않고, 바로 직접 모델 구현하기.