MAP, NDCG
비즈니스 / 서비스 관점
추천 시스템 적용으로 인해 매출, PV(Page View) 증가
추천 아이템으로 인해 유저 CTR(노출 대비 클릭)의 상승
품질 관점
-
정확성(Accuracy)
-
연관성(Relevance): 추천된 아이템이 유저에게 관련이 있는가?
-
다양성(Diversity): 추천된 Top-K 아이템에 얼마나 다양한 아이템이 추천되는가?
-
신뢰성(Confidence) : 추천 결과를 제공하는 시스템이 신뢰할 만한가?
표준편차가 적은 추천 시스템일수록 더 높은 Confidence를 가진다.
-
신뢰성(Trust) : 사용자가 추천 결과에 얼마나 믿음을 가지는가?
추천 결과에 설명이 추가된다면 사용자가 추천 결과를 더 믿게 된다.
Novelty와 Trust는 Trade-off 관계에 있다.
사용자가 이미 알고 있거나 좋아하는 아이템을 추천하면 추천 결과에 대한 신뢰도가 올라간다.
-
적용 범위(Coverage): 추천되는 아이템이 전체 중 얼마나 차지하는가?
-
개인화(Personalization): 개인화된 아이템이 추천되고 있는가?
-
새로움(Novelty): 얼마나 새로운 아이템이 추천되고 있는가?
인기 항목만 추천하는 경우를 줄이기 위해 사용
-
참신함(Serendipity): 유저가 기대하지 못한 뜻밖의 아이템이 추천되는가?
- Serendipity ≠ novelty (un-awareness)
- Serendipity = novelty + relevance + unexpectedness
-
강인함(Robustness & Stability)
-
Scalability : 추천 시스템이 대용량 데이터 및 트래픽을 효과적이고 효율적으로 처리할 수 있는가?
평점 예측 평가
(user, item) 쌍에 대한 compatibility score를 직접 예측한다.
RMSE: Root Mean Squared Error
MAE: Mean Absolute Error
AUC
랭킹 평가
Top-K Ranking은 user별로 예측된 compatibility score 순서에 따라 ranked list of items를 생성한다.
User Study
사용자들을 모집해서 시스템과 상호작용하게 한 후 피드백을 수집한다.
활발한 사용자 참여에 바탕을 두고 있기 때문에, 실제 사용환경과 동떨어지는 경우도 있다.
균일한 집단을 만들기 위해선 많은 시간과 비용이 소모되기 때문에, 현실적으로 적용하기가 쉽지 않다.
Offline Test
이미 수집된 데이터 (historical datasets)를 활용하여 알고리즘의 성능을 평가하는 방법
과거 데이터를 바탕으로 모델의 성능을 파악한다.
새로운 추천 모델을 검증하기 위해 가장 우선적으로 수행되는 단계
유저로부터 수집한 데이터를 train/valid/test로 나누어 모델의 성능을 객관적인 지표로 평가
- 데이터 분할 전략에 따라서 시스템 성능 평가에 큰 영향을 줄 수 있다.
- 상황에 맞는 적절한 분할 전략이 필요
데이터 분할 전략
-
Leave One Last
사용자당 마지막 구매를 Test set으로, 마지막에서 2번째를 Valid set으로 분할
-
장점
학습 시 많은 데이터 사용 가능
-
단점
- 사용자당 마지막 구매로만 평가하므로 테스트 성능이 전체적인 성능을 반영한다고 보기 어렵다.
- 훈련 중에 모델이 테스트 데이터 상호작용을 특징으로 학습할 가능성 존재
-
-
Temporal User / Global Split
시간을 이용한 분할 전략
- Temporal User
- 사용자 별로 시간 순서에 따라 일정 비율로 데이터 분할
- Leave One last와 유사
- Data leakage 문제
- Temporal Global (권장됨)
- 각 유저 간에 공유되는 시점을 고정하여, 특정 시점 이후에 이뤄진 모든 상호작용을 test set으로 분할
- 학습 및 검증에 사용할 수 있는 상호작용이 적은 문제
- 현실과 가장 유사한 평가 환경을 제공
- Temporal User
-
Random Split
각 사용자 별 interaction을 random하게 아이템을 선택하여 분할
- 사용하기 쉬움
- 많은 train set
- Data leakage 문제
-
User Split
사용자가 겹치지 않게 사용자를 기준으로 분할
- Cold-start 문제에 대응하는 모델 생성 가능
- User-free 모델에만 사용 가능
- Future Data leakage 문제
-
CV: Cross Validation(교차 검증)
보통 offline test에서 좋은 성능을 보여야 online test에 투입된다.
실제 서비스 상황에서는 다양한 양상을 보인다.(serving bias)
한계
- 결측값을 아무리 추론한다고 하더라도, 실제 유저가 좋아할지 싫어할지는 알 수 없다.
- 데이터 수집 이후, 시간의 흐름에 따라 사용자 선호도 및 아이템의 특성이 변화하는 것을 반영할 수 없다.
- accuracy 관련 지표만으로는 serendipity 및 novelty 와 같은 추천 시스템의 중요한 특성을 포착할 수 없다.
- 추천 시스템에 존재하는 feedback loop로 인해 다양한 bias들이 증폭되기 때문에 부정확한 상대평가로 이어질 수 있다.
- Data Bias
- Selection Bias
Precision/Recall/MAP@K
Precision@K
우리가 추천한 K개 아이템 가운데 실제 유저가 관심있는 아이템의 비율
def precision_at_k(actual, predicted, k):
act_set = set(actual)
pred_set = set(predicted[:k])
result = len(act_set & pred_set)
# normalized_prec = result / float(min(len(act_set),k))
return prec
Recall@K
유저가 관심있는 전체 아이템 가운데 우리가 추천한 아이템의 비율
def recall_at_k(actual, predicted, k):
act_set = set(actual)
pred_set =set(predicted[:k])
result = len(act_set & pred_set) / float(len(act_set))
return result
ex) 우리가 추천한 아이템 개수: 5(=K)
추천한 아이템 중 유저가 관심있는 아이템 개수: 2
유저가 관심있는 아이템의 전체 개수: 3
$\tt Precision@5 = 2/5$
$\tt Recall@5 = 2/3$
AP@K
Precision@1부터 Precision@K까지의 평균값
Precision@K와 달리, 관련 아이템을 더 높은 순위에 추천할수록 점수가 상승한다.
$$
A P @ K=\frac{1}{m} \sum_{i=1}^K \text { Precision@i }
$$
MAP(Mean AP)@K
모든 유저에 대한 Average Precision 값의 평균
$$
M A P @ K=\frac{1}{|U|} \sum_{u=1}^{|U|}(A P @ K)_u
$$
nDCG: Normalized Discounted Cumulative Gain
추천 시스템에 가장 많이 사용되는 지표 중 하나
검색(IR)에서 등장한 지표.
Precision@K, MAP@K와 마찬가지로 Top K 리스트를 만들고 유저가 선호하는 아이템을 비교하여 값을 구한다.
MAP@K와 마찬가지로 추천의 순서에 가중치를 더 많이 두어 성능을 평가하며, 1에 가까울수록 좋다.
MAP와 달리, 연관성을 이진값이 아닌 수치로도 사용할 수 있다.
유저에게 얼마나 더 관련 있는 아이템을 상위로 노출시키는지 알 수 있다.
CG
상위 K개 아이템의 관련도를 합한 것
순서에 따라 Discount하지 않고, 동일하게 더한 값
`$$ C G_K=\sum_{i=1}^K r e l_i
$$`
DCG
순서에 따라 Cumulative Gain을 Discount한다.
$$
D C G_K=\sum_{i=1}^K \frac{r e l_i}{\log _2(i+1)}
$$
Ideal DCG
이상적인 추천이 일어났을 때의 DGC값
즉, DCG의 최대값
`$$
I D C G=\sum_{i=1}^K \frac{r e l_i^{o p t}}{\log _2(i+1)}
$$`
Normalized DCG
$$
N D C G=\frac{D C G}{I D C G}
$$
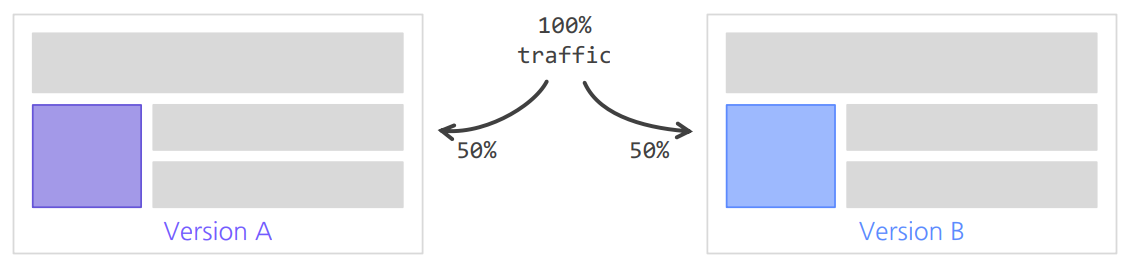
Online A/B Test
동시에 대조군 A와 B의 성능을 평가한다.
(대조군과 실험군의 환경은 최대한 동일해야 한다.)
실제 서비스를 통해 얻어지는 결과를 통해 최종 의사결정이 이루어진다.
대부분 현업에서 의사결정에 사용하는 최종 지표는 모델 성능이 아닌 매출, CTR 등의 비즈니스/서비스 지표
MRR: Mean Reciprocal Rank
$$
M R R=\frac{1}{|U|} \sum_{u \in U} \frac{1}{\operatorname{rank}_u\left(i_u\right)}
$$