- 정보 필터링(IF) 기술의 일종.
- 특정 사용자가 관심 가질 만한 정보를 추천하는 것.
Background
기존
유저가 원하는 것을 검색하여 이에 맞는 아이템 결과를 보여주는 Pull 방식
추천 시스템
유저가 원하는 것을 유추하여 제시하는 Push 방식
유저가 자신의 니즈를 쿼리로 표현하지 않아도 된다.
다양한 종류의 아이템들을 유저에게 노출시킬 수 있다.
추천 시스템의 필요성
과거에는 유저가 접할 수 있는 상품, 컨텐츠가 제한적
TV 채널, 영화관, 백화점, 신문 등
웹/모바일 환경에 의해 다양한 상품, 컨텐츠 등장 → 정보 과다.
일부 유명한 아이템이 많이 소비되는 것(The Long Tail Phenomenon)이 아니라, 아주 많은 Long Tail 아이템이 추천을 통해 소비된다.(Long Tail 추천)
정보를 찾는데 시간이 오래 걸린다.
유저가 원하는 걸 어떤 키워드로 찾아야 하는지 모를 수 있다.
Long Tail Recommendation 사례
- 유튜브 동영상 추천
- SNS 친구 추천
추천 시스템의 목적
- 정보 수집, 탐색 시간 단축하기
- 선택의 폭을 넓히기
유저 → 아이템
특정 유저에게 적합한 아이템을 추천
아이템 → 유저
특정 아이템에게 적합한 유저 추천
추천시스템에서 사용하는 정보
-
유저 관련 정보
-
유저 프로파일링
추천 대상 유저에 관련된 정보를 구축하여, 개별 유저 혹은 유저 그룹별로 추천
-
식별자(Idendifier)
유저 ID, 디바이스 ID, 브라우저 쿠키
-
데모그래픽 정보
성별, 연령, 지역, 관심사
-
유저 행동 정보
페이지 방문 기록, 아이템 평가, 구매 등의 피드백 기록
-
-
아이템 관련 정보
추천 아이템 종류
- 포탈: 뉴스, 블로그, 웹툰 등 컨텐츠 추천
- 광고/커머스: 광고 소재, 상품 추천
- 미디어: 영화, 음악, 동영상 추천
아이템 프로파일링
- 아이템 ID
- 아이템의 고유정보
- Content base Recommendation에서는 아이템의 고유정보만 활용하기도 한다.
-
상호작용 정보(유저 — 아이템)
유저와 아이템의 상호작용 데이터
유저가 온/오프라인에서 아이템과 상호작용할 때 발생하는 로그
추천 시스템을 학습하는 데이터의 Feedback이 된다.
Explicit Feedback
유저에게 아이템에 대한 만족도를 직접 물어본 경우
ex) 영화에 대한 평점
Implicit Feedback
유저가 아이템을 클릭하거나 구매한 경우
ex) 쿠팡에서 아이템을 구매하면 → Implicit feedback = Y
추천 Task
랭킹(Ranking)
유저에게 적합한 아이템 Top K개를 추천하는 문제
평가 지표: Precision@K, Recall@K, MAP@K, nDCG@K
- Top K개를 선정하기 위한 기준 혹은 Score 필요하다.
- 유저(X)가 아이템(Y)에 가지는 정확한 선호도를 구할 필요는 없다.
Top-k Ranking 문제는 0과 1의 binary-value로 이뤄진 implicit feedback을 예측하는 태스크에 주로 사용된다.
예측(Prediction)
유저가 아이템에 가질 선호도를 정확하게 예측(평점 or 클릭/구매 확률)
평가 지표: MAE, RMSE, AUC
- Explicit Feedback: 철수가 아이언맨에 대해 내릴 평점값을 예측
- Implicit Feedback: 영희가 아이폰12를 조회하거나 구매할 확률을 예측
- 유저 — 아이템 행렬을 채우는 문제
real-value로 이뤄진 explicit feedback을 예측하는 태스크에 주로 사용된다.
추천 시스템 특징
- 도메인에 대한 높은 의존성
- 도메인 지식에서 비롯된 인사이트가 많다.
- 다양한 데이터를 볼 수 있는 기회에 대한 중요성이 크다.
- 폐쇄적인 데이터
- 대상 데이터인 User Data와 Item Data는 대부분 기업 내부의 기밀 사항에 해당한다.
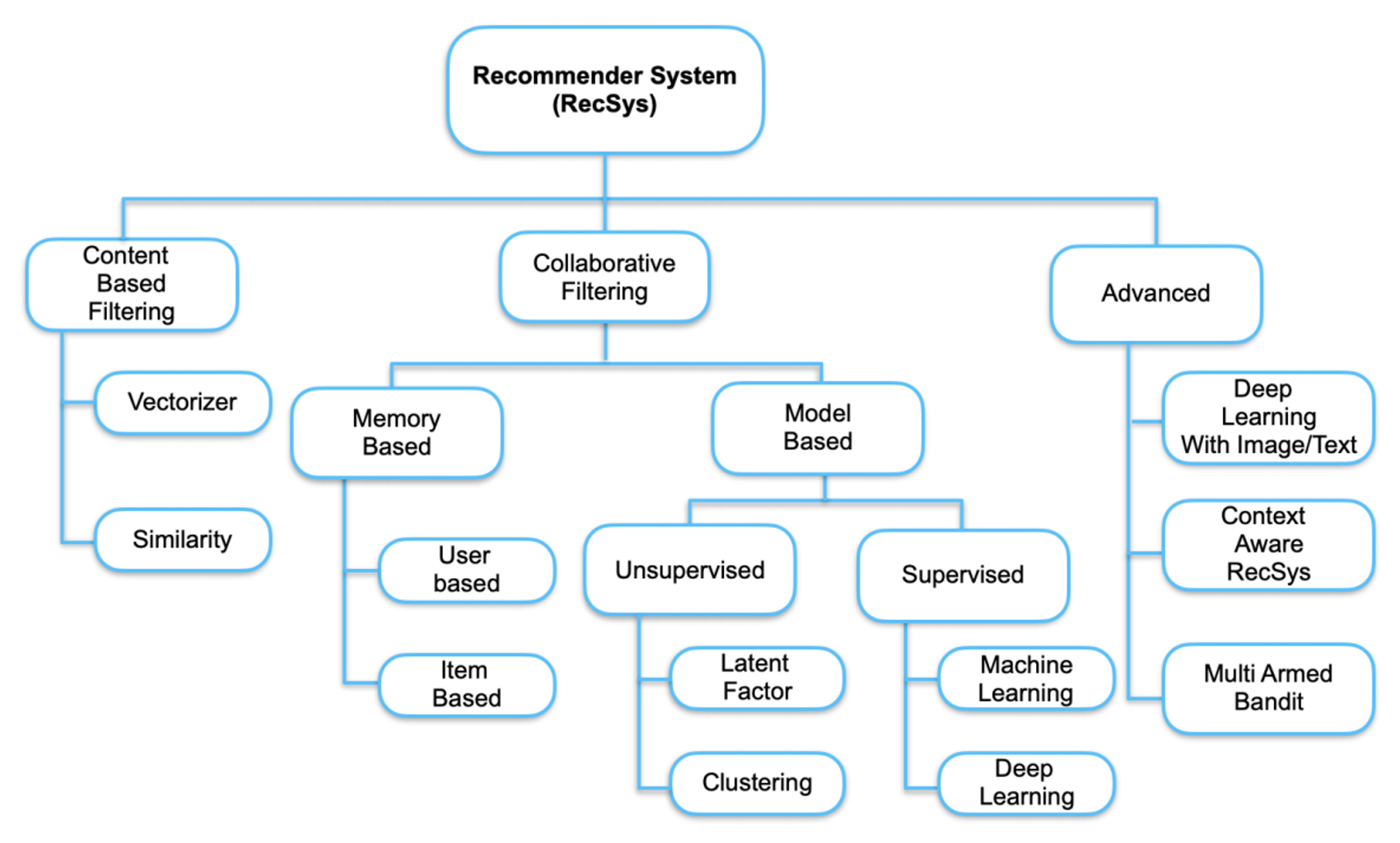
추천 시스템 종류
- Simple Aggregate (popularity, average score, recent uploads)
- Association Analysis
- Content-based Recommendation
- Collaborative Filtering
- Item2Vec Recommendation and ANN
- Deep Learning-based Recommendation
- Context-aware Recommendation
- Multi-Armed Bandit(MAB)-based Recommendation
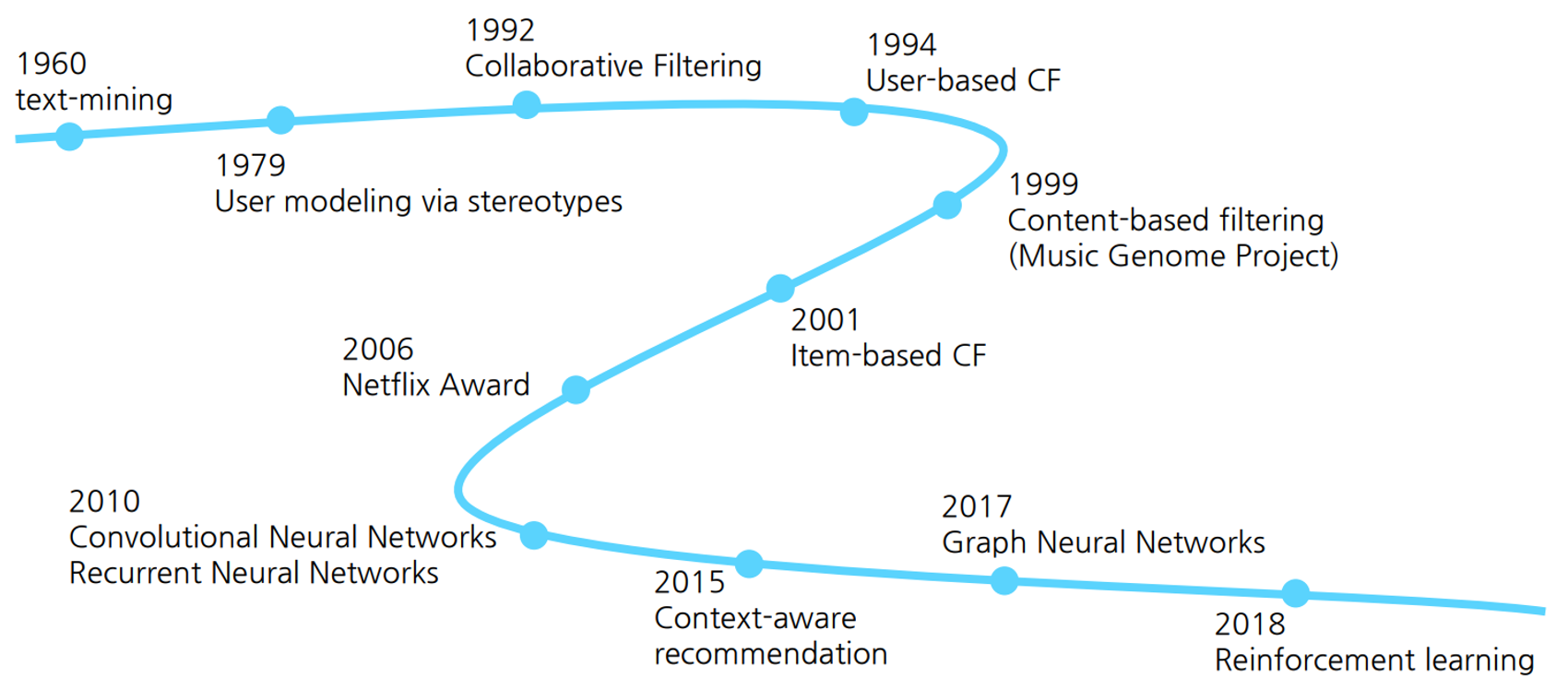
추천 시스템에서는 ML을 주요하게 사용한다.
-
ML의 성능을 압도하는 DL이 아직 나오지 않았다.
-
많은 유저가 사용하는 Service에서 큰 트래픽을 감당해야 한다.
최대한 가벼운 모델을 쓰게 된다.
추천 시스템의 분석 프로세스
Preprocessing
- Data Transform
- Data Split
- Data Split Strategy
- Random split by ratio
- Random split by user
- Leave one out split
- Split by timepoint
Model
- Content-Based Filtering
- Collaborative Filtering
- Context Aware Recommendation
- Hybrid(Content-Based Filtering + Collaborative Filtering)
Evaluation
Prediction — Explicit Feedback을 예측하는 태스크에 주로 사용
- MAE
- MSE
- RMSE
Rank — Implicit Feedback을 예측하는 태스크에 주로 사용
- Precision@K
- Recall@K
- AP@K
- MAP@K
- NDCG@K