연관 규칙 분석(Association Rule Analysis)
추천 시스템의 가장 고전적인 방법론
장바구니 분석, 서열 분석이라고도 불린다.
상품의 구매, 조회 등 하나의 연속된 거래들 사이의 규칙을 발견하기 위해 적용하는 방법
즉, 사용자의 장바구니 내에 포함된 상품들의 규칙을 발견하기 위해 적용하는 방법
유저 정보(유저 행동 정보)를 활용하는 분석 방법
규칙
IF {condition} THEN {result}
{condition} → {result}
연관 규칙
규칙 가운데 일부 기준(빈번함의 기준)을 만족하는 것
IF {antecedent} THEN {consequent}
빈번하게 발생하는 규칙을 의미한다.
ex) {기저귀} → {맥주}
{우유} → {빵}
이 때, 화살표는 연관 관계를 나타낼 뿐, 인과관계를 의미하지 않는다.
Itemset
연관규칙을 구성하는 상품의 집합(antecedent, consequent)
하나 이상의 집합으로 구성
antecedent와 consequent는 disjoint(서로소)를 만족해야 한다.
k-itemset: k개의 item으로 이루어진 itemset
support count($\sigma$)
전체 transaction data에서 itemset이 등장하는 횟수
$\tt \sigma(\text\{빵,\ 우유\}) = 3$
support
itemset에서 전체 transaction data에서 등장하는 비율
-
support count로 계산된 값.
support({빵, 우유}) = 3 / 5 = 0.6
-
연관 규칙에서 가장 중요한 값.
frequent itemset
유저가 지정한 minimum support 값 이상의 itemset
minimum support 값을 넘지 못한 itemset은 infrequent itemset이라고 부른다.
연관 규칙의 척도
frequent itemset들 사이의 연관 규칙을 만들기 위해서 measurement가 필요하다.
$X\rightarrow Y$가 존재할 때, $(X,Y : \text{itemset, N: 전체 transaction 수})$
-
support
두 itemset
$X,Y$를 모두 포함하는 transaction의 비율즉, 전체 transaction에 대한 itemset의 확률값
좋은 규칙을 찾거나, 불필요한 연산을 줄일 때 사용된다.
-
confidence
$Y$의$X$에 대한 조건부 확률confidence가 높을수록 유용한 규칙이다.
-
lift
[
$X$가 포함된 transaction가운데$Y$가 등장할 확률] / [$Y$가 등장할 확률]1을 기준으로 나타난다.
0~1 사이의 값이 아니다.
-
$\tt lift = 1 ⇒ X,Y\ 독립$ -
$\tt lift > 1 ⇒ X,Y\ 양의\ 상관관계$ -
$\tt lift < 1 ⇒ X,Y\ 음의\ 상관관계$ -
예시
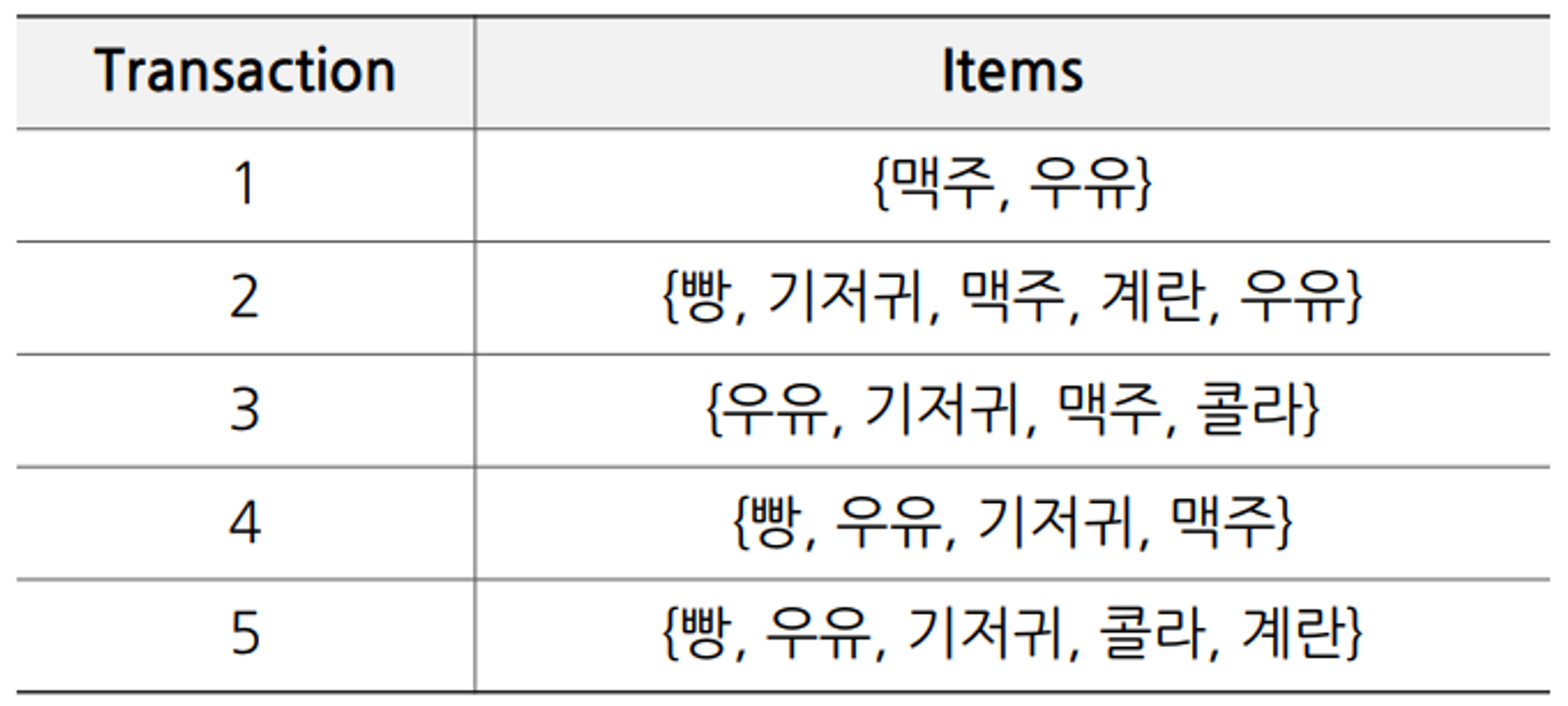
X = 빵, Y = 계란
-
support
$$ \begin{aligned}s(X \rightarrow Y)&=\frac{n(X \cup Y)}{N}=P(X \cap Y)\\&=\frac{n(2,5)}{5}=0.4 \end{aligned} $$ -
confidence
$$ \begin{aligned} c(X \rightarrow Y)&=\frac{n(X \cup Y)}{n(X)}=\frac{n(2,5)}{n(2,4,5)}=0.66 \\& =P(Y \mid X)=\frac{P(X \cap Y)}{P(X)}=\frac{0.4}{0.6}=0.66\end{aligned} $$ -
lift
$$ \begin{aligned} l(X \rightarrow Y)=\frac{c(X \rightarrow Y)}{s(Y)}&=\frac{0.66}{0.4}=1.66 \\& =\frac{P(X \cap Y)}{P(X) P(Y)}=\frac{s(X \rightarrow Y)}{s(X) s(Y)}=\frac{0.4}{0.6 \cdot 0.4}=1.66\end{aligned} $$
-
-
연관 규칙의 사용
Item 수가 많아질수록, 가능한 itemset에 대한 rule의 수가 기하급수적으로 많아진다.
이 중 유의미한 rule만 사용해야 한다.
-
minimum support, minimum confidence로 의미없는 rule을 screen out
전체 transaction 중에서 너무 적게 등장하거나, 조건부 확률이 아주 낮은 rule을 필터링한다.
-
lift값으로 내림차순 정렬 후 의미있는 rule을 평가한다.
사용자 입장에서 lift값을 사용하면 더 만족스러운 추천을 얻게 된다.
-
ex) 와인(
$X$), 와인 오프너($Y$), 생수($Z$)라고 할 때,$P(Y|X) = 0.1$,$P(Z|X) = 0.2$인 경우위 수식만 봤을 땐, 와인을 샀을 때 오프너가 아닌 생수를 살 확률이 더 높다.
$P(Y) = 0.01$$P(Z) = 0.2$하지만, 각 물건을 살 확률을 기반으로 lift값을 계산하게되면 와인 — 와인오프너의 lift값이 10이 되고, 와인 — 생수의 lift값은 1이 된다.
lift가 크다는 것은 rule을 구성하는 antecedent와 consequent가 연관성이 높고 유의미하다는 뜻
-
연관 규칙의 탐색(Mining Association Rules)
주어진 트랜잭션 가운데, 아래 조건을 만족하는 가능한 모든 연관 규칙을 찾는다.
- support ≥ minimum support
- confidence ≥ minimum confidence
가장 쉽게 떠올리는 방법은 Bruth force.
하지만 연산량이 너무 커서 매우 비효율적이다.
효율적인 Association Rule Mining을 위한 단계
-
Frequent Itemset Generation
minimum support 이상의 모든 itemset을 생성한다.
연산량이 가장 많다.
연관 분석에서 가장 중요하다.
생성 전략
-
가능한 후보 itemset의 개수를 줄인다.
- Apriori Algorithm : 가지치기를 활용하여 탐색해야 하는 M을 줄인다.
-
탐색하는 transaction의 숫자를 줄인다.
Itemset의 크기가 커짐에 따라 전체 N개 transaction보다 적은 개수를 탐색한다.
-
탐색 횟수를 줄인다.
효율적인 자료구조를 사용하여 후보 itemset과 transaction을 저장한다.
모든 itemset과 transaction의 조합에 대해 탐색할 필요가 없다.
-
-
Rule Generation
minimum confidence 이상의 association rule을 생성한다.
이 때, rule을 이루는 antecedent와 consequent는 서로소를 만족해야 한다.